...
| 锚 | ||||
|---|---|---|---|---|
|
^【数据集】优化SQL语句编辑器
...
背景介绍
V9.6及之后版本,我们优化了SQL数据集和原生SQL数据集中的SQL语句编辑器,使业务人员在编写SQL语句时,能够更加规范、易用、美观。6版本,我们优化了SQL数据集和原生SQL数据集中的SQL语句编辑器,使业务人员在编写SQL语句时,能够更加规范、易用、美观。
功能简介
对SQL语句编辑器的优化如下:
- 支持关键字高亮显示;
- 支持关键字输入提示;
- 支持代码折叠;
- 兼容之前编辑器中的对象展示模式;
- 增加辅助工具:如查找(Ctrl+H)、替换(Ctrl+F)等;
- 增加根据参数值快速实现SQL语句的拼接操作(IF函数)。
...
目前引擎调度策略是把实验作为整体进行调度,实验中的节点无法脱离出来独立执行。若引擎能够按照节点粒度进行调度,这样会给引擎在功能和扩展性方面带来好处。
功能简介
V9.6及之后的版本,引擎按照节点粒度进行调度,可以带来以下几点优势:6版本,引擎按照节点粒度进行调度,可以带来以下几点优势:
- 可以做到断点续跑,如果在数据量大的情况下,会节省很大时间,提高实验的效率;
- 能单独执行一个节点,在实验的设计跟调式阶段带来很大便利
- 可以对单节点进行资源控制,防止某个节点占用资源太大,对其它节点造成影响
- 调度更加灵活,同个实验中的不同节点,可以在不同机器中执行
- 部署架构扩张性更好,可以横向扩张节点的执行机器
...
kafka是一种高吞吐量的分布式发布订阅消息系统,经常用于实时流数据架构,提供实时分析。它具有高吞吐量、低延迟,每秒可以处理几万条消息,延迟最低只有几毫秒,以及可扩展性、持久性、可靠性、容错性、高并发等优点。因此,SmartSmartbi在V9.6版本新增了Kafka数据源。
功能简介
Kafka作为数据源,有以上三种使用场景:
...
在数据挖掘过程中,原始数据的不均匀分布会影响到数据特征抽取,或者模型学习数据特征的效果,出现错判的情况,我们会对数据进行重采样,对原始数据进行初步加工,对出现频次较高的数据按照一定规则抽取一定数据使得整体分布均匀。
功能简介
V9.6及之后的版本新增下采样节点,可通过移除数据量较多类别的部分数据,使样本达到均衡。6版本新增下采样节点,可通过移除数据量较多类别的部分数据,使样本达到均衡。

详情参考
关于数据挖掘的下采样,详情请参考 采样 。
...
无论是机器学习还是数据分析,总是要面对一大堆数据,总是免不了出现异常值的可能性,,异常值可以大幅度地改变数据分析和统计建模的结果,可能会造成回归、方差分析等统计模型假设的基本假设受影响等问题。
功能简介
V9.6及之后的版本新增异常值处理节点,可对存在异常的数据进行检测和识别,且对识别出的异常值进行处理。6版本新增异常值处理节点,可对存在异常的数据进行检测和识别,且对识别出的异常值进行处理。

详情参考
关于数据挖掘的异常值处理,详情请参考 异常值处理。
...
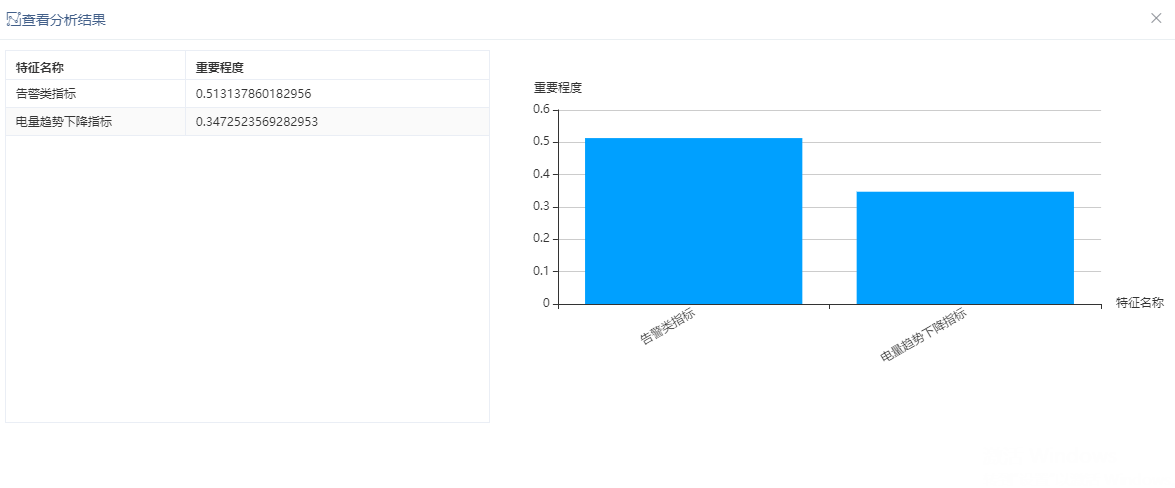
GBDT是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终答案。V9.6及之后的版本,左侧资源树特征过程节点下新增GBDT特征选择节点。6版本,左侧资源树特征过程节点下新增GBDT特征选择节点。

输出特征选择后的特征及其重要程度,以柱图展示如下:
...
高维数据是指具有多个属性的数据,它在我们日常生活中十分常见,比如各种类型的多媒体数据、文档词频数据等等。面对这些高维数据,我们该如何展示各种属性之间的联系和发现它们之间的规律。其实在过去的数十年里,可视化领域已经产生了大量优秀的技术,如散点图矩阵、平行坐标图等,以帮助用户分析这类数据。
功能简介
V9.6及之后的版本新增高维数据可视化节点,支持通过矩阵图和平行坐标图对高维数据进行可视化分析。6版本新增高维数据可视化节点,支持通过矩阵图和平行坐标图对高维数据进行可视化分析。

矩阵图效果:

平行坐标图效果:

详情参考
关于数据挖掘的高维数据矩阵,详情请参考 数据挖掘-高维数据矩阵。
...
RFM节点通过对选择的特征列按照阈值进行二分(可按均值、指定值、中值),将客户数据划分为不同的客群。V9.6及之后的版本,左侧资源树统计分析节点下新增RFM节点。6版本,左侧资源树统计分析节点下新增RFM节点。

详情参考
详情参考数据挖掘-RFM。
| 锚 | ||||
|---|---|---|---|---|
|
...
词向量节点作为文本处理常用的特征工程手段、在情感分析、语义分析上可以用来增加模型准确性、计算相似性等功能。V9.6及之后的版本,左侧资源树文本分析节点下新增词向量节点。6版本,左侧资源树文本分析节点下新增词向量节点。

在查看输出结果可以看到每个文本对应的词向量:
详情参考
...
LDA主题模型主要用来推测文档的主题分布,它可以将文档集中每篇文档的主题以概率分布的形式给出,从而通过分析一些文档抽取出它们的主题分布后,便可以根据主题分布进行主题聚类或文本分类。 V9.6及之后的版本,左侧资源树文本分析节点下新增LDA和主题6版本,左侧资源树文本分析节点下新增LDA和主题-词分布(LDA)节点。

详情参考
详情参考数据挖掘-主题-词分布(LDA)。
...
在挖掘实验过程中,对每一个执行完的节点资源我们都可以预览该节点的数据,如果可以将预览数据导出到本地,这将便于用户进行后续的处理或分析。
功能简介
V9.6及之后的版本支持预览数据导出到本地,在查看输出窗口新增“下载预览数据”选项。6版本支持预览数据导出到本地,在查看输出窗口新增“下载预览数据”选项。

注意事项
此处会把预览的数据以csv文件的方式下载到本地,不会下载全量数据,数据量最多100条。
...
在实际应用中,用户在编辑自助仪表盘的TAB页组件时,选择内部组件的工具栏操作比较麻烦。为了简化操作并提升用户体验感,V9.6及以后版本我们增强了自助仪表盘的TAB页组件功能。6版本我们增强了自助仪表盘的TAB页组件功能。
功能简介
1、调整组件工具栏:
1)去掉内部组件工具栏,改为在页签或页签的下拉菜单中设置组件(不同的组件类型的设置项不同)。
...
之前的版本,在自助仪表盘中筛选器或图表组件默认只能与同名字段自动关联,而在实际应用中,需要设置不同数据源的筛选器之间的关联。为了满足上述场景,V9.6及以后版本我们优化了自助仪表盘组件之间联动关系的设置。6版本我们优化了自助仪表盘组件之间联动关系的设置。
功能简介
1、全局联动关系设置:
自主仪表盘工具栏中,增加 联动设置 按钮,可设置两个及两个以上的数据集/业务主题字段之间的联动关系。
...
之前产品内置的时间函数较少,业务人员通常需要写SQL语句来获取需要的时间函数,这种方式比较麻烦、实用性不高。V9.6及以后版本我们新增了一些简单易用的时间函数,可以满足业务人员需要:版本我们新增了一些简单易用的时间函数,可以满足业务人员需要:
- 不需要写SQL语句,可以直接使用日期函数对象;
- 灵活性高,可满足不同场景的应用。
...


