一、升级前须知
在升级Smartbi之前,我们需要先阅读以下产品升级前的流程操作。
1、容灾备份
在任何情况下的Smartbi升级,都是需要先进行容灾备份的。说明如下:
备份范围 | 补充说明 |
|---|---|
知识库备份 | 1.通过Smartbi备份知识库,在Smartbi选择 系统运维 > 备份知识库; 2.通过数据库工具备份数据库。 |
war包备份 | 无 |
授权许可文件备份 | 无 |
| borderColor | #BBBBBB |
|---|---|
| bgColor | #F0F0F0 |
| borderWidth | 1 |
| borderStyle | solid |
2、预升级测试
在正式升级Smartbi之前,一般还需要进行预升级测试,可以选择先搭建测试环境或者基于现有的开发环境来进行这一步操作。
| 注意 |
|---|
| 在测试环境上未测试通过的情况下,最好不要直接对生产环境进行操作,以防对生产环境造成损坏。 |
3、评估定制功能
如果在升级Smartbi的过程中有通过二次开发实现的定制功能,那在升级之前我们需要考虑这几个点:
1. 定制扩展包的兼容性;
2. 评估二次开发的代码升级代价;
3. 环境依赖和功能变化对现在项目使用的影响;
因此,在升级之前需要先联系定制部门去评估定制功能的兼容升级。
二、升级后的变化
1、更新License
背景:V9.6版本的Smartbi,在授权文件License中增加了对新功能模块的控制。
操作:在升级Smartbi之前,需要联系Support技术支持获取对应版本的License文件,然后上传到升级后的Smartbi系统中,实现更新License文件。
2、限制报表导出文件的时间
背景:为了避免用户在导出大数据量查询时候导致对服务器资源压力过大、占用大量带宽。

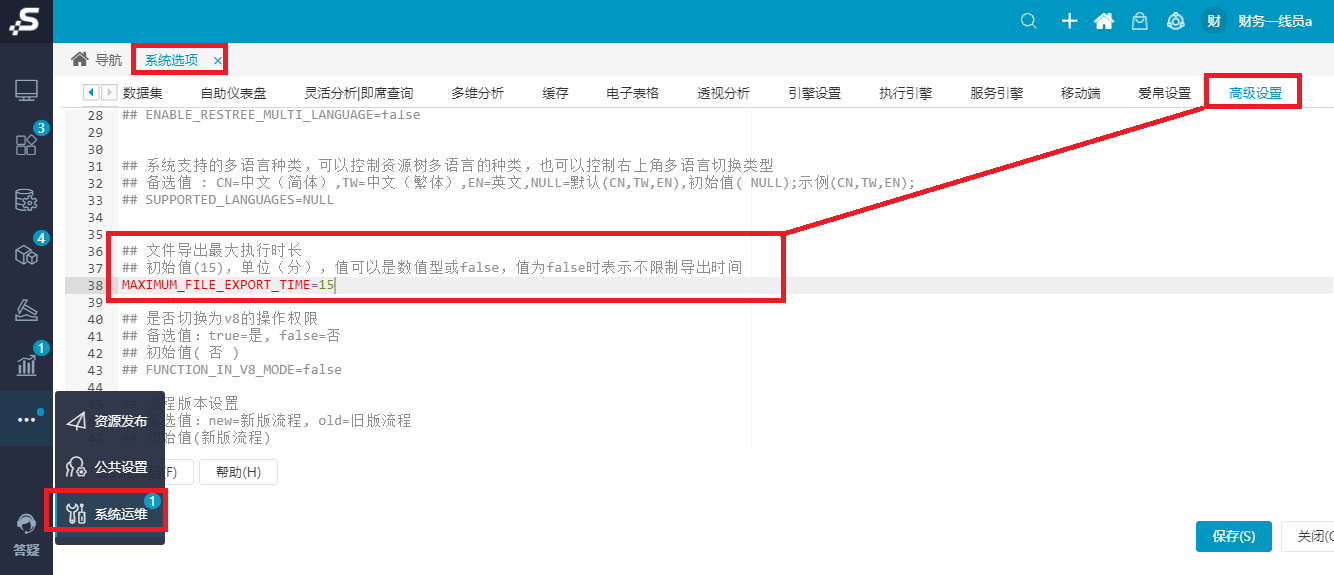
功能入口:进入Smartbi选择 系统运维 > 系统选项 > 高级设置 。在“高级设置”界面中增加设置项“文件导出最大执行时长”。
设置项内容为:初始值为15,单位:分钟。这个值可以是数值型或false,值为false时表示不限制导出时间。支持用户根据实际情况进行修改。
| 注意 |
|---|
| 通过计划任务设置的导出报表,不受文件导出最大执行时长限制。 |
3、修改数据挖掘实验节点中间数据的存储逻辑
3.1 增加HDFS的部署
如果在使用Smartbi的过程中使用了数据挖掘模块,则需要进行数据挖掘引擎的更新升级。
因为新版本修改了实验节点中间数据的存储逻辑,实现了“对于任何节点,只要它上游节点执行完成,都可以从该节点执行,不需要从头开始执行”。
由于使用HDFS存储节点数据,因此升级需要在默认部署环境中增加HDFS的部署。
HDFS的部署方法如下:
部署环节 | 步骤详情 | |||||||
|---|---|---|---|---|---|---|---|---|
准备hadoop数据目录 | 1、创建临时目录:
2、创建namenode数据目录
3、创建datanode 数据目录 注意:这个目录尽量创建在空间比较大的目录,如果有多个磁盘,可以创建多个目录
| |||||||
解压Hadoop到安装目录 |
| |||||||
修改hadoop配置 | 1、修改hadoop-env.sh
2、找到JAVA_HOME,修改为如下所示:
3、找到export HADOOP_OPTS, 在下面添加一行
4、修改core-site.xml
内容如下:
5、修改hdfs-site.xml
内容如下: 注意:dfs.data.dir尽量配置在空间比较大的目录,可以配置多个目录,中间用逗号分隔
| |||||||
配置hadoop环境变量 |
在最底下添加下面内容:
让配置生效
|
详细的升级文档请参见: 安装Hadoop组件 。
3.2 升级Spark
升级Spark到3.0版本有以下两种方式:
3.3 升级数据挖掘
升级数据挖掘有以下两种方式:
- 安装包部署: 数据挖掘引擎V95升级V96版本注意事项
- 高性能版本部署:高性能版本-数据挖掘V95升级V96注意事项
4、UI调整
1)数据源按照以下顺序排序:
- “全部”标签页中,数据库分为“常用数据库”与“所有数据库”:常用数据库:按数据库的新建次数由高到低排序;所有数据库:按照字母顺序排序。
- “本地数据库、关系数据库、多维数据库、NoSQL数据库”页签中,所有数据库按照字母顺序排序。
- Other数据源不按字母排序,位置在所有数据库和关系数据库最后。
2)在系统设置页面右上角增加麦粉社区的链接,链接到麦粉社区首页。
5、功能影响
1)优化自助仪表盘组件联动:
删除筛选器应用于组件的“高级设置”选项、“合并参数”选项,所有的联动关系都在全局的联动设置中设置。
2)重申引用权限的定义:
有资源的引用权限,则能进行数据读取,但在资源树上不显示。
3)增加授权快捷入口:
在报表的资源授权界面添加“引用依赖资源”、“高级授权”按钮,点击 引用依赖资源 可以一键授予其依赖资源的引用权限。
4)合并旧的编辑权限和删除权限为一个资源权限——编辑。
5)Insight升级到Eagle需手动更改浏览器tab图标:
从Insight升级到Eagle,浏览器的tab图标还是显示Insight的,需要手动去改成Eagle。


