(1) 获取数据,数据来源于赛题二手车交易价格预测;
(2) 对获取的数据进行基本的处理操作,相关性分析输入特征;
(3) 根据统计特征数据建立二手车交易价格预测模型;
(4) 对模型结果进行评估。
实施过程
本案例共收集到15万条二手车历史数据,字段详细说明如下表所示:
字段名称 | 类型 | 字段说明 |
|---|---|---|
SaleID | 整型 | 交易ID,唯一编码 |
name | 整型 | 汽车交易名称,已脱敏 |
regDate | 整型 | 汽车注册日期,例如20160101,2016年01月01日 |
model | 浮点型 | 车型编码,已脱敏 |
brand | 整型 | 汽车品牌,已脱敏 |
bodyType | 浮点型 | 车身类型:豪华轿车:0,微型车:1,厢型车:2,大巴车:3,敞篷车:4,双门汽车:5,商务车:6,搅拌车:7 |
fuelType | 浮点型 | 燃油类型:汽油:0,柴油:1,液化石油气:2,天然气:3,混合动力:4,其他:5,电动:6 |
gearbox | 浮点型 | 变速箱:手动:0,自动:1 |
power | 整型 | 发动机功率:范围 [ 0, 600 ] |
kilometer | 整型 | 汽车已行驶公里,单位万km |
notRepairedDamage | 字符串 | 汽车有尚未修复的损坏:是:0,否:1 |
regionCode | 整型 | 地区编码,已脱敏 |
seller | 整型 | 销售方:个体:0,非个体:1 |
offerType | 整型 | 报价类型:提供:0,请求:1 |
creatDate | 整型 | 汽车上线时间,即开始售卖时间 |
price | 整型 | 二手车交易价格(预测目标) |
v系列特征 | 整型 | 匿名特征,包含v0-14在内15个匿名特征 |
数据接入
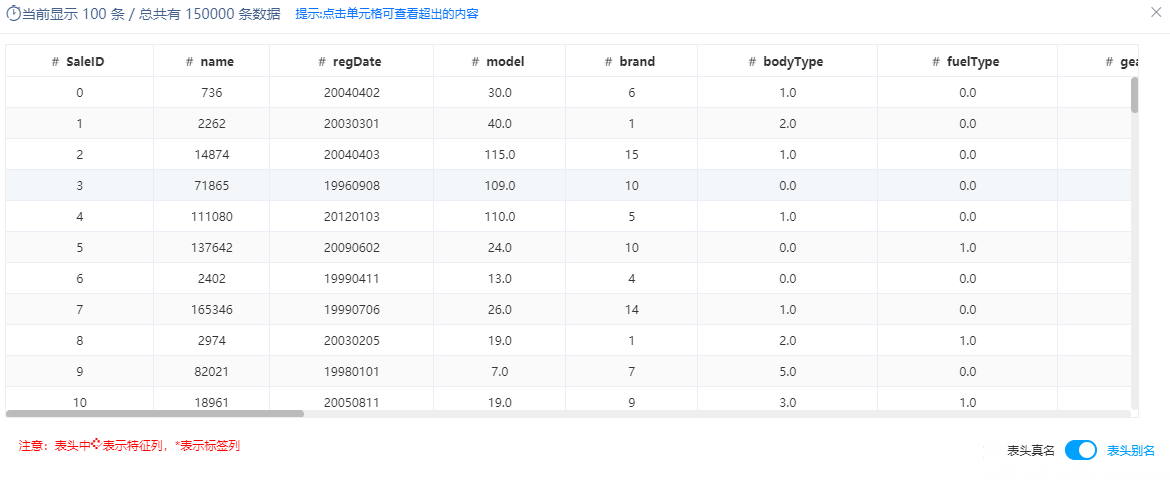
在实验中添加数据源节点,将二手车交易价格数据读取进来,部分数据如图所示:
数据探索
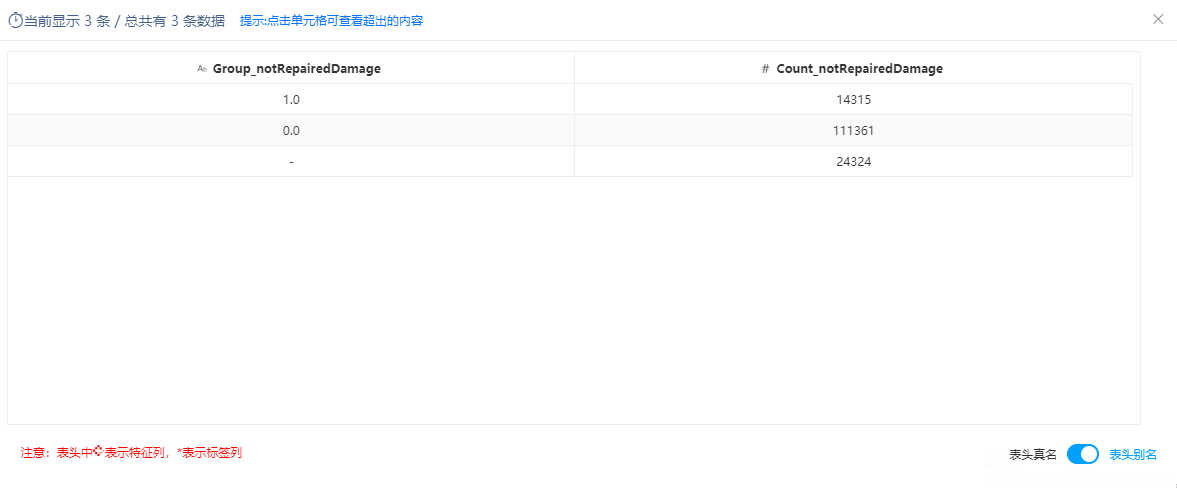
本案例的探索分析是对数据进行缺失值分析与数据分布分析,分析出数据的缺失和分布情况。通过聚合节点查看原表数据中notRepairedDamage字段类型有三种。需要将“-”的数据设置为空值。
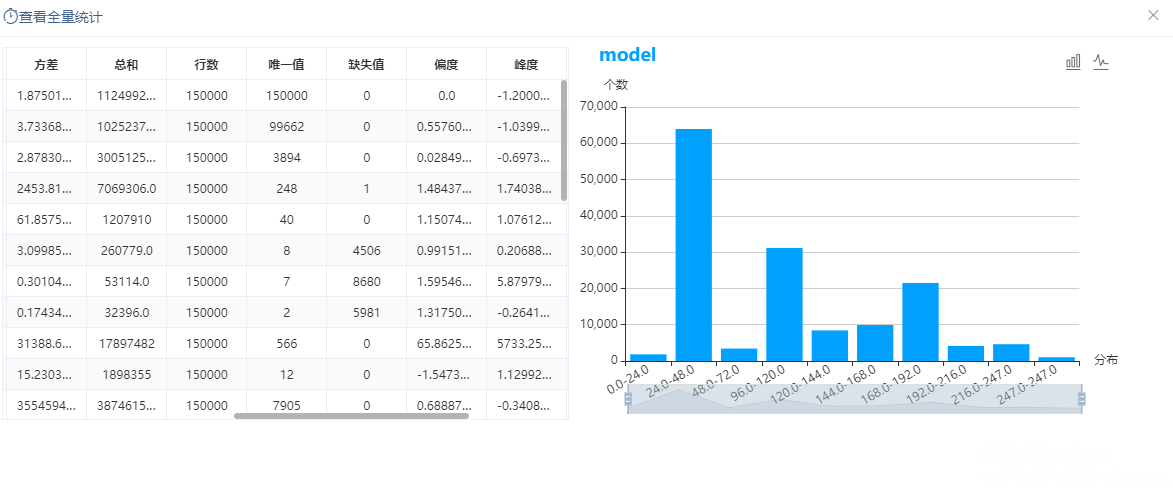
通过全表统计节点统计所有特征,查看各指标的分布情况,发现部分数据含有缺失情况,如图:
数据预处理
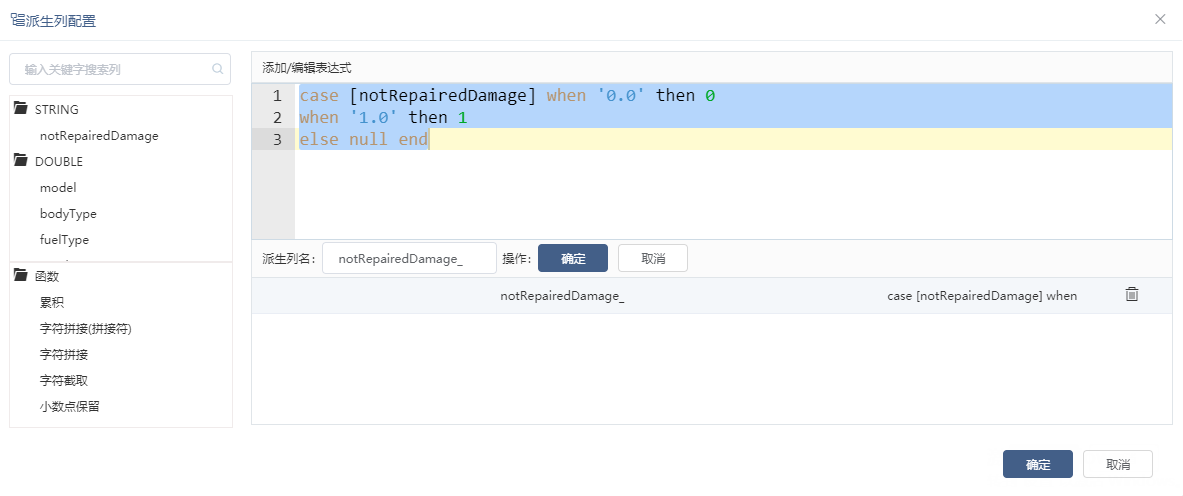
我们通过派生列节点对notRepairedDamage字段中“-”值转换为空值处理,如图:
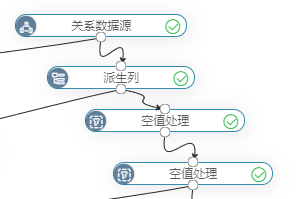
根据全表统计查看缺失数据分布情况,对正态分布数据使用平均值填补,右偏分布的数据使用中位数填充处理。整个的数据预处理流程图如图所示:
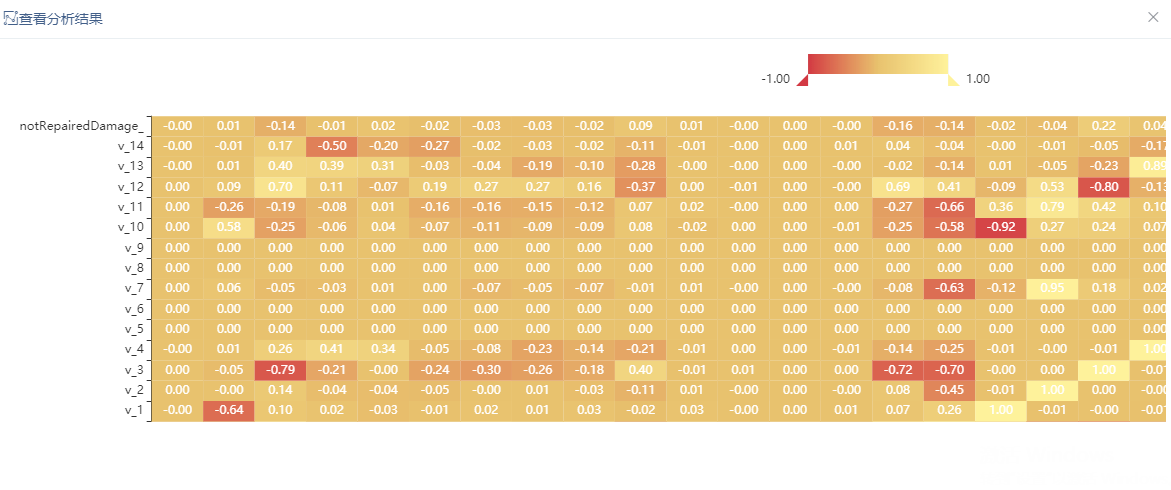
相关性分析
通过相关性分析节点,相关性分析部分结果如图所示:
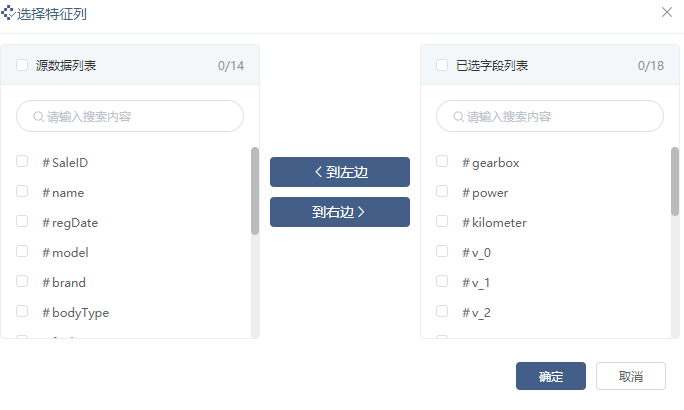
我们特征选择相关性系数较高的特征输入模型,特征选择如图:
建立模型
本案例采用梯度提升回归树算法对模型进行训练,使用拆分节点按照7:3的比例将数据集拆分为训练集和测试集。整体的流程图如图所示:
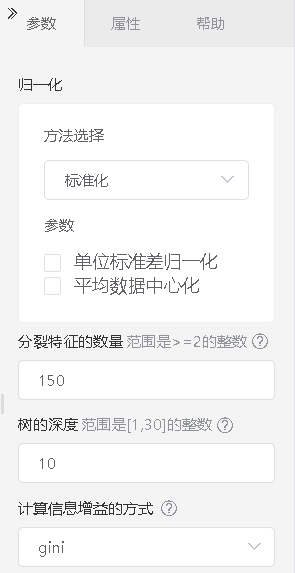
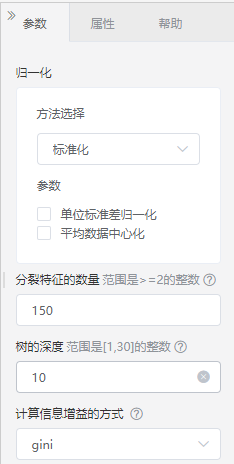
算法参数配置如图:
模型训练后预测的结果如图:
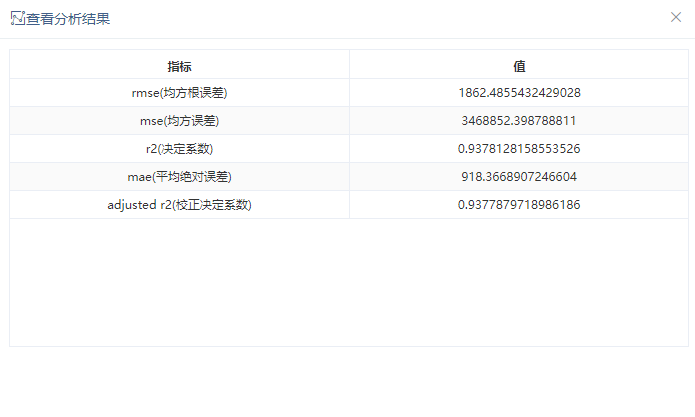
模型评估
接入评估节点对模型进行评估,评估结果如图所示。R2大概为0.94。
业务分析
我们通过GBDT特征选择节点输出重要性较高的10个特征,结果如图:
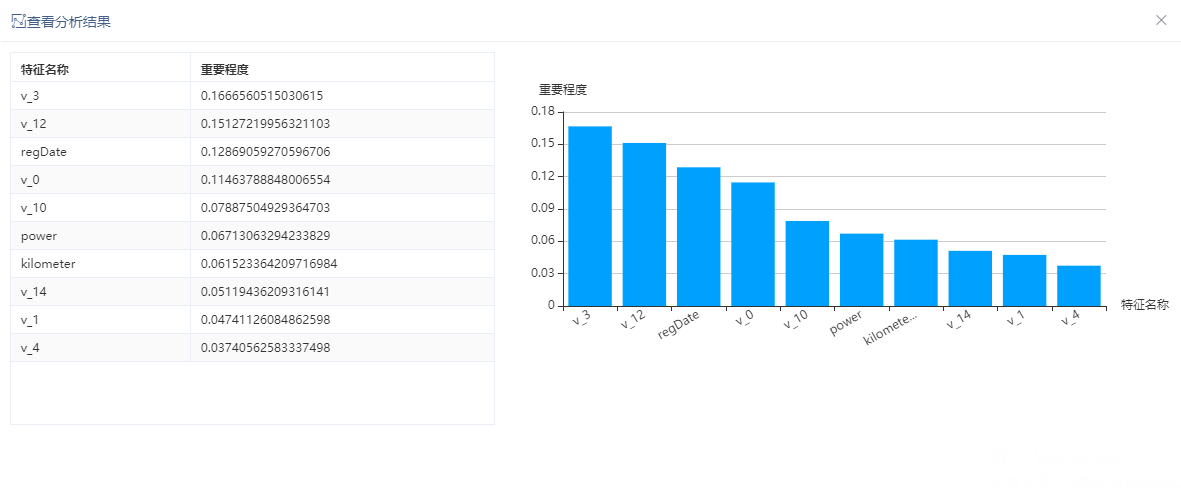
分析发现v_3、v_12、regDate等几个特征是影响二手车交易价格的因素。
总结
本案例结合二手车交易价格预测案例,重点介绍了梯度提升回归树预测分析在实际案例中的应用。本案例借助二手车交易历史记录建立模型预测二手车交易未来价格,二手车价格市场;针对影响二手车交易价格因素,可以做好相关的优惠活动。


