新特性列表中:+表示新增 ;^表示增强;<表示变更。
数据准备
(待完善)^【数据集】优化SQL语句编辑器数据准备
背景介绍
V9.7及之后版本,我们优化了SQL数据集和原生SQL数据集中的SQL语句编辑器,使业务人员在编写SQL语句时,能够更加规范、易用、美观。
功能简介
对SQL语句编辑器的优化如下:
- 支持关键字高亮显示;
- 支持关键字输入提示;
- 支持代码折叠,实现了括号之间的内容的折叠;
- 支持在编辑器中对象的拖拽、复制和删除;
- 支持提示表、字段、系统函数、数据库函数等的ID、类型和路径;
- 在 函数列表>系统函数>逻辑函数 中,增加IF函数,可用来动态拼接动态的SQL语句。
示例:显示关键字高亮显示和输入提示,如图:

分析展现
(待完善)^【自助仪表盘】优化自助仪表盘组件联动设置
背景介绍
之前的版本,在自助仪表盘中筛选器或图表组件默认只能与同名字段自动关联,而在实际应用中,需要设置不同数据源的筛选器之间的关联。为了满足上述场景,V9.7及以后版本我们优化了自助仪表盘中筛选器和图表组件的联动设置。
功能简介
1、设置全局联动关系:
在自助仪表盘工具栏中,增加 联动设置 按钮,可设置需要联动的数据集及联动关系:

支持两种方式设置组件之间的联动关系:
- 自动:自动匹配选择数据集所有的源字段和目标字段。
- 自定义:手动添加联动数据集的源字段、目标字段、操作符。

2、在筛选器组件的 更多 中,影响报表和应用于组件:
- 增加“相关数据集所有组件”、“此数据集所有组件”、“自定义”选项;
- 删除“高级设置”、“合并参数”选项。

注意事项
1、仪表盘需要有两个以上业务主题/数据集,才可以点击联动设置;否则,不可点。
2、互相联动的两个数据集/业务主题,联动设置中页面展示的自动/自定义、联动字段数量/名称、操作符一致。
数据挖掘
+【挖掘】新增多层感知机算法节点
背景介绍
数据中潜藏的规律按照以往的聚类,回归等传统分析手段很难被发现,Smartbi Mining新增多层感知机算法节点。多层感知机(MLP,Multilayer Perceptron)也叫人工神经网络(ANN,Artificial Neural Network),通过神经网络中的节点和隐藏层对数据特征进行‘学习’,并以模型形式保存,用于分类、预测等使用场景。
功能简介
多层感知机作为多分类算法节点与其他机器学习节点同样使用。
详情参考 多层感知机 。
+【挖掘】增加下采样节点
背景介绍
在数据挖掘过程中,原始数据的不均匀分布会影响到数据特征抽取,或者模型学习数据特征的效果,出现错判的情况,我们会对数据进行重采样,对原始数据进行初步加工,对出现频次较高的数据按照一定规则抽取一定数据使得整体分布均匀。
功能简介
详情参考 采样 。
+【挖掘】增加节点备注功能
背景介绍
机器学习实验往往牵涉多个节点,各节点之间关系也较为复杂,更或者自定义的算法节点只有实验构建者才明白其中的含义,不便于实验的交流,故增加节点及实验备注功能。
功能简介
在画布空白处单击,选择‘添加备注’,会弹出富文本编辑框,可以添加对实验背景的介绍等内容。

+【挖掘】支持节点复制选项
背景介绍
实验构建过程中,可能出现节点复用的情况,由于涉及到参数的配置问题,所以增加节点的复制功能,将大大提高实验的构建速度。
功能简介
选中需要复制的节点,单击右键,出现‘复制’,也可以同时选中多个节点:
- 拖动鼠标覆盖需要选择的节点,箭头滑过的矩形区域的节点都被选中;
- 按住Crtrl键,鼠标逐个单击需要复制的节点。

+【挖掘】新增kafka数据源节点
背景介绍
kafka是一种高吞吐量的分布式发布订阅消息系统,经常用于实时流数据架构,提供实时分析。它具有高吞吐量、低延迟,每秒可以处理几万条消息,延迟最低只有几毫秒,以及可扩展性、持久性、可靠性、容错性、高并发等优点。因此,Smart在V9.7版本新增了Kafka数据源。
功能简介
Kafka作为数据源,有以上三种使用场景:
- 准实时的数据处理:通过任务调度,持续消费kafka数据,提供给一系列数据处理节点进行处理,处理后的结果可以输出到目标数据库
- 模型自学习:通过任务调度,持续消费kafka数据进行模型自学习
- 模型批量预测:通过任务调度,定时消费kafka数据进行批量预测
这里展示当Kafka作为数据源时的模型自学习:

^【挖掘】新增新建、编辑数据集入口
背景介绍
目前Smartbi的挖掘模块中,数据集节点只有选择数据集功能,为了方便用户可以在挖掘的实验界面中新建和编辑数据集,V9.7版本新增了新建、编辑数据集的入口。
功能简介
V9.7版本在数据集节点的参数设置界面新增了新建、编辑数据集的入口。

+【挖掘】新增异常值处理节点
背景介绍
无论是机器学习还是数据分析,总是要面对一大堆数据,总是免不了出现异常值的可能性,,异常值可以大幅度地改变数据分析和统计建模的结果,可能会造成回归、方差分析等统计模型假设的基本假设受影响等问题。
功能简介
之后的版本新增异常值处理节点,可对存在异常值的原始数据进行异常值处理。
其他
+【系统函数】新增时间函数
背景介绍
之前产品内置的时间函数较少,业务人员通常需要写SQL语句来获取需要的时间函数,这种方式比较麻烦、实用性不高。V9.7及以后版本我们新增了一些简单易用的时间函数,可以满足业务人员需要:
- 不需要写SQL语句,可以直接使用日期函数对象;
- 灵活性高,可满足不同场景的应用。
功能简介
1、产品的内置函数中新增了19个时间函数,如图:

2、在定义中改变函数设置方式:新增编辑框可手动添加参数值或拖拽函数;并增加预览功能。

注意事项
1、在参数定义中,不支持写SQL语句获取时间函数。
2、在 系统选项>电子表格>水印 中, “内容”设置项不支持使用新增的时间函数。
3、即席查询、透视分析等资源的表头表尾中,不适用新增的时间函数。
^【无状态】产品支持无状态化
背景介绍
以前的版本,用户在web端或者插件端编辑报表没有进行保存时,如果有人重启了服务器,则用户会丢失刚才编辑的报表和操作。为了解决这类问题并提升产品性能和拓展性,我们在V9.7及之后的版本产品支持无状态化,即无论服务器是否重启,用户可以一直编辑报表和执行操作。
功能简介
在系统配置页面中,新增会话缓存及“缓存的服务器地址”设置项。
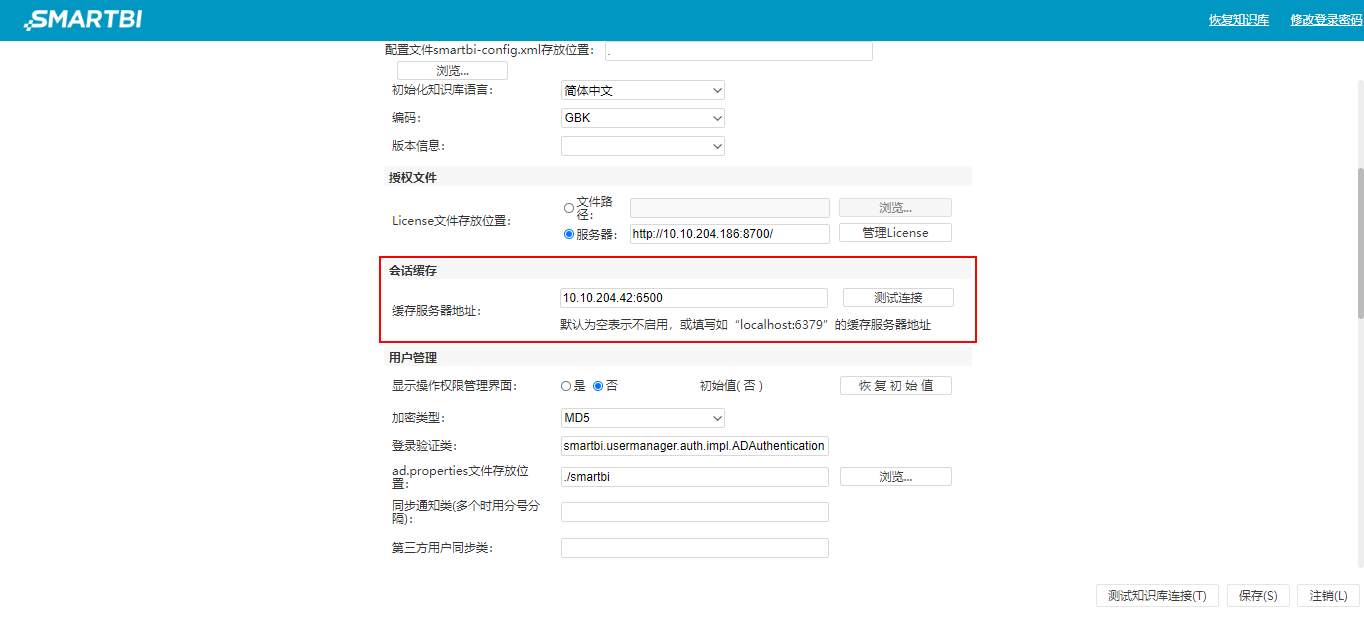
注意事项
缓存的服务器为Redis。当多个Smartbi连接同一个服务器时,需要配置服务器的时间相同(默认相差5分钟)。


