数据挖掘执行引擎:
- 负责接收smartbi 发送执行请求。
- 通过解析执行定义,生成spark 计算任务或python计算任务,分别发送给spark集群或python集群。
- 本身并不承担计算任务,只负责计算任务的调度跟分发。
数据挖掘服务引擎:
- 提供模型预测服务给第三放系统调用
数据挖掘执行引擎和服务引擎可部署在同一台服务器中,也可以分开部署在不同服务器中。
| 注意 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||
文档中单机数据挖掘部署环境如下:
PS:可根据实际服务器资源,将数据挖掘及其组件部署在不同服务器,或者部署在同一台服务器中(可能导致性能下降). |
1、系统环境准备
1.1防火墙配置
为了便于安装,建议在安装前关闭防火墙。使用过程中,为了系统安全可以选择启用防火墙,但必须启用服务相关端口。
(1)关闭防火墙
临时关闭防火墙
| 代码块 | ||
|---|---|---|
| ||
systemctl stop firewalld |
永久关闭防火墙
| 代码块 | ||
|---|---|---|
| ||
systemctl disable firewalld |
查看防火墙状态
| 代码块 | ||
|---|---|---|
| ||
systemctl status firewalld |
(2)开启防火墙
相关服务及端口对照表:
| 服务名 | 需要开放端口 |
|---|---|
执行引擎 | 8899 |
| 服务引擎 | 8900 |
如果确实需要打开防火墙安装,需要给防火墙放开以下需要使用到的端口
开启端口:8899,8900
| 代码块 | ||
|---|---|---|
| ||
firewall-cmd --zone=public --add-port=8899/tcp --permanent firewall-cmd --zone=public --add-port=8900/tcp --permanent |
配置完以后重新加载firewalld,使配置生效
| 代码块 | ||
|---|---|---|
| ||
firewall-cmd --reload |
查看防火墙的配置信息
| 代码块 | ||
|---|---|---|
| ||
firewall-cmd --list-all |
(3)关闭selinux
临时关闭selinux,立即生效,不需要重启服务器。
| 代码块 | ||
|---|---|---|
| ||
setenforce 0 |
永久关闭selinux,修改完配置后需要重启服务器才能生效
| 代码块 | ||
|---|---|---|
| ||
sed -i 's/=enforcing/=disabled/g' /etc/selinux/config |
1.2 安装Java环境
安装包解压到/opt目录
| 代码块 | ||
|---|---|---|
| ||
tar -zxvf jdk8.0.202-linux_x64.tar.gz -C /opt |
配置java环境变量
①执行 vi ~/.bash_profile 在文件末尾添加java环境变量参数,并保存
| 代码块 | ||
|---|---|---|
| ||
export JAVA_HOME=/opt/jdk8.0.202-linux_x64 export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/jre/lib:$CLASSPATH export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH |
②使配置生效
| 代码块 | ||
|---|---|---|
| ||
source ~/.bash_profile |
③查看java版本信息
| 代码块 | ||
|---|---|---|
| ||
java -version |
1.3取消打开文件限制
修改/etc/security/limits.conf文件在文件的末尾加入以下内容:
| 代码块 | ||||
|---|---|---|---|---|
| ||||
vi /etc/security/limits.conf |
在文件的末尾加入以下内容:
| 代码块 | ||||
|---|---|---|---|---|
| ||||
* soft nofile 65536 * hard nofile 65536 * soft nproc 131072 * hard nproc 131072 |
2、部署数据挖掘引擎
| 注意 | ||
|---|---|---|
| ||
2.1 修改主机名-添加映射关系
根据部署实际环境,各个服务器主机名不同即可不修改主机名,如需修改,可参考下面的修改方式:
| 代码块 | ||||
|---|---|---|---|---|
| ||||
hostnamectl set-hostname 主机名 |
PS:主机名不能使用下划线
配置主机名和IP的映射关系
| 代码块 | ||||
|---|---|---|---|---|
| ||||
vi /etc/hosts |
内容设置,例如:
| 代码块 | ||||
|---|---|---|---|---|
| ||||
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.137.139 smartbi-engine 192.168.137.140 smartbi-python 192.168.137.141 smartbi-spark |
| 注意 | ||
|---|---|---|
| ||
部署smartbi的服务器的/etc/hosts,需要添加所有数据挖掘节点的主机和IP地址映射 |
2.2 安装数据挖掘-执行引擎
1、解压Smartbi-engine安装包到指定的安装目录
| 代码块 | ||||
|---|---|---|---|---|
| ||||
tar -zxvf SmartbiMiningEngine-V9.6.57367.20296.tar.gz -C /opt |
| 注意 |
|---|
所解压的Smartbi-engine安装包版本需和Smartbi版本对应 |
2、启动数据挖掘执行引擎
| 代码块 | ||||
|---|---|---|---|---|
| ||||
cd /opt/smartbi-mining-engine-bin/engine/sbin/ chmod +x *.sh ./experiment-daemon.sh start |
2.3 安装数据挖掘-服务引擎
| 注意 | ||
|---|---|---|
| ||
由于文档中服务引擎与实验引擎部署在同一台服务器,所以无需重复设置系统环境。 如果服务引擎与实验引擎部署在不同服务器时,服务引擎系统环境设置可参考实验引擎的配置。 |
1、启动数据挖掘服务引擎
| 代码块 | ||||
|---|---|---|---|---|
| ||||
cd /opt/smartbi-mining-engine-bin/engine/sbin/ ./service-daemon.sh start |
2.4测试数据挖掘
第一步:数据挖掘执行引擎连接测试:
| 注意 |
|---|
引擎和服务所在的主机名不能带有小数点或下划线。 |
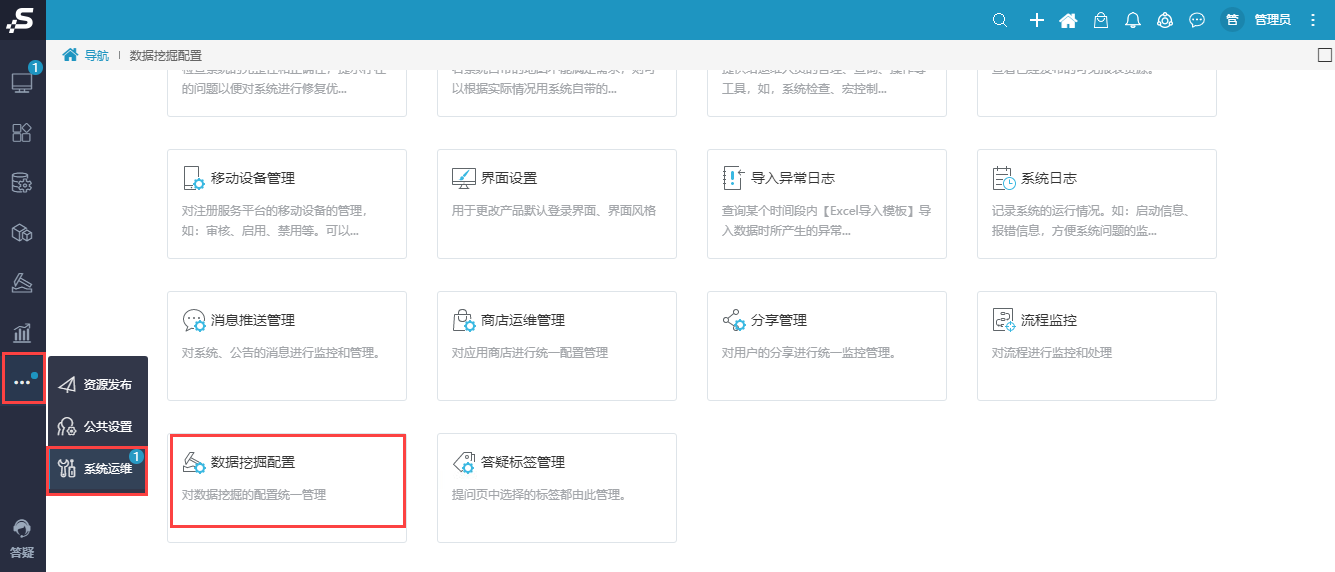
(1)浏览器访问Smartbi,打开系统运维-数据挖掘配置
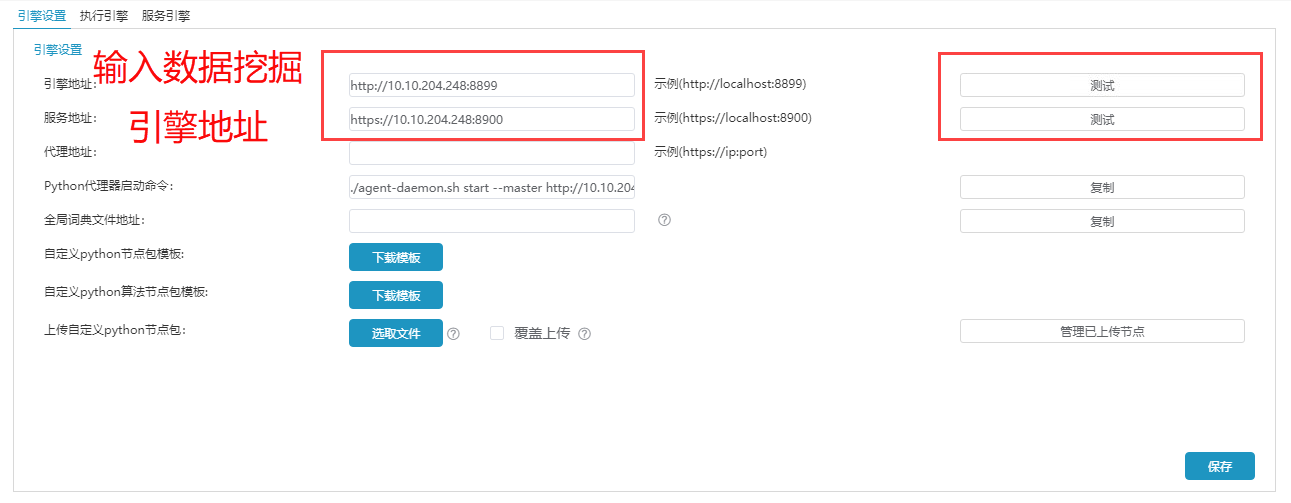
(2)在引擎设置页面输入引擎地址和服务地址后,点击测试连接
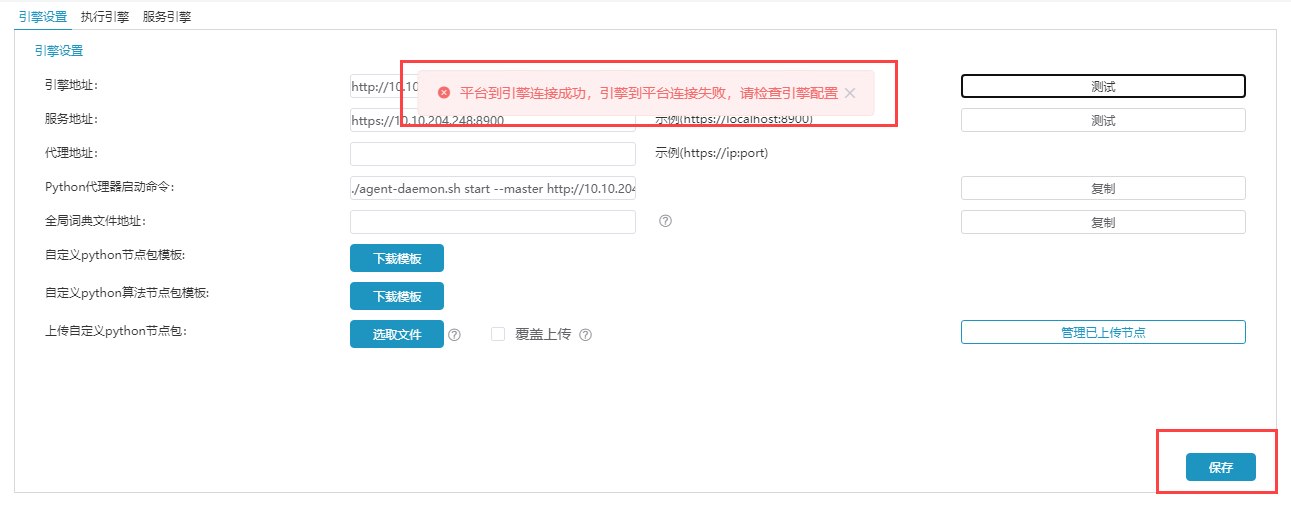
由于第一次部署数据挖掘服务,当前引擎不知道smartbi服务器的实际地址,所以会提示“平台到引擎连接成功,引擎到平台连接失败,请检查引擎配置”的警告。需要先点击保存按钮,然后再到执行引擎和服务引擎设置smartbi的地址,并保存。最后回到引擎设置点击 测试连接 才能提示“平台和引擎双向连通”
| 注意 |
|---|
如果测试连接后没有保存,则执行引擎和服务引擎可能会显示空白页面 |
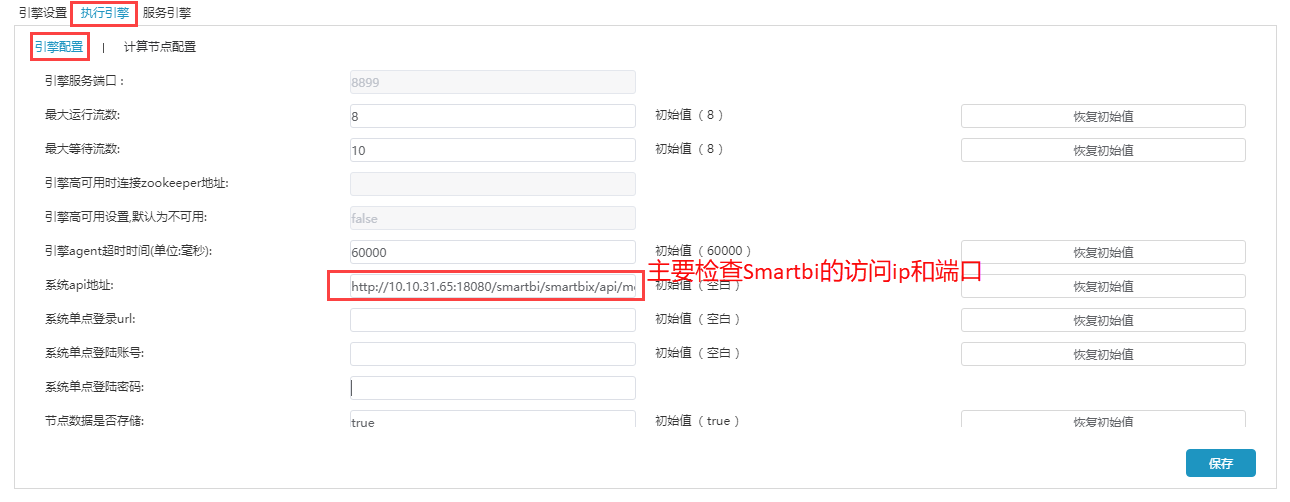
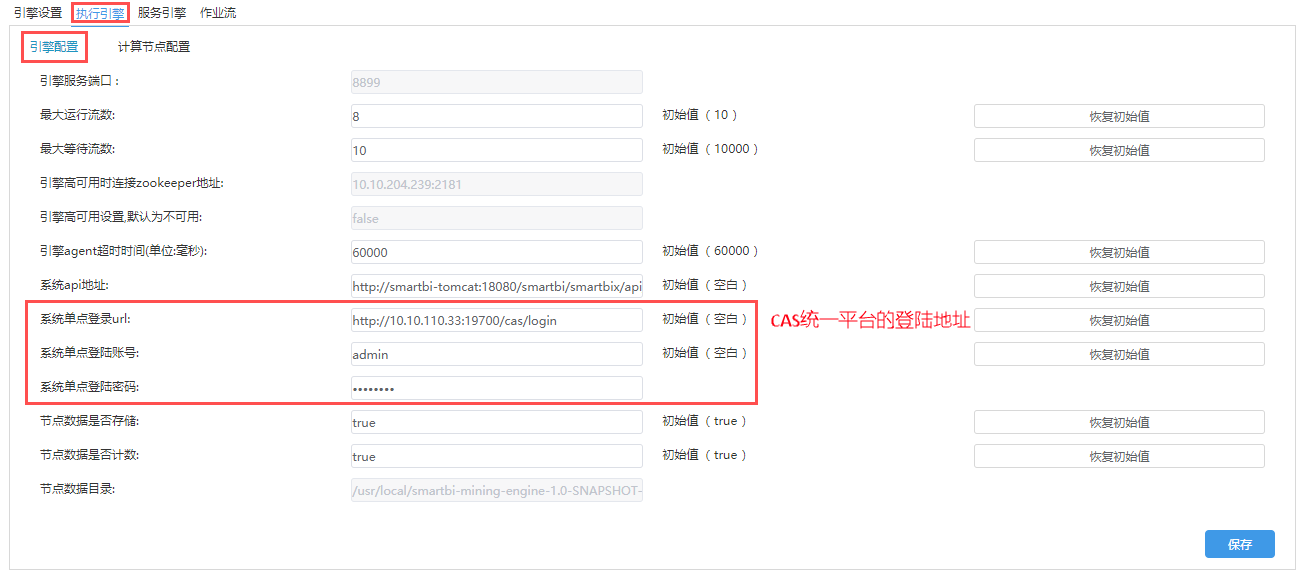
(3)打开执行引擎--引擎配置,如下图所示(具体配置根据实际部署环境修改):
| 注意 | |||||||
|---|---|---|---|---|---|---|---|
如果Smartbi配置了如果Smartbi版本为v9.5且配置了CAS单点登录,如下图所示(具体配置根据实际部署环境修改):
|
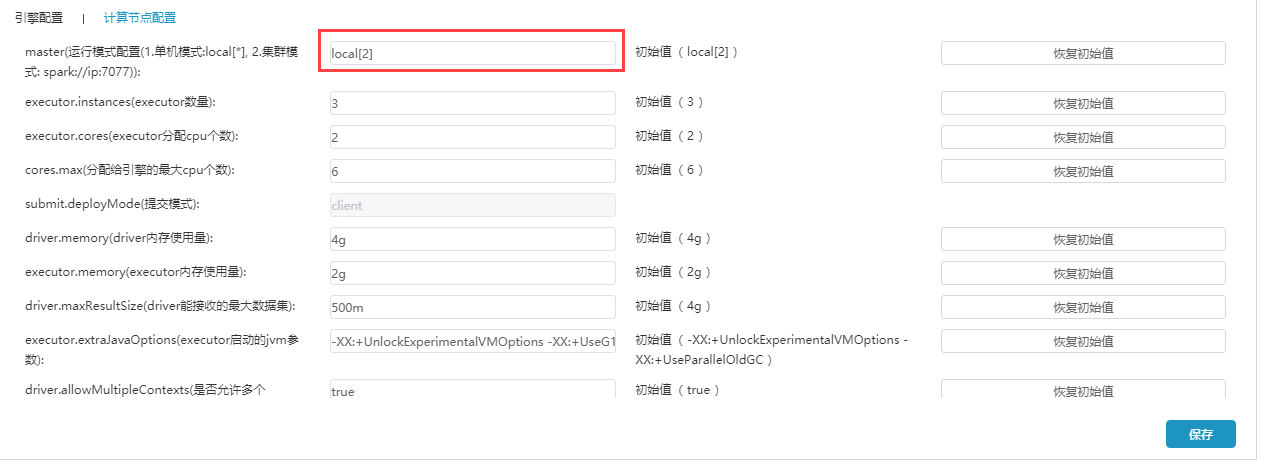
(4)打开执行引擎--计算节点配置,如下图所示:(如未部署Spark,计算节点配置使用初始值)
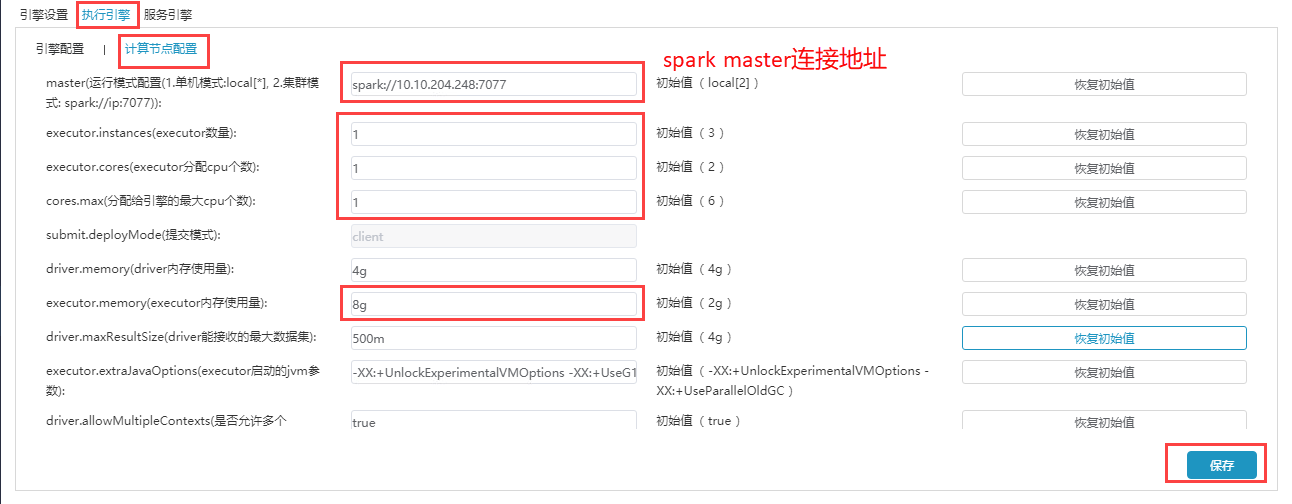
若当前已部署好Spark,计算节点配置如下图所示:(具体配置根据实际部署环境修改):
重点配置红框地方,第一个框填写spark master连接地址,其它选项配置策略如下:
- executor.instances * executor.memory <= spark可分配的内存数 * 0.7(例如 52G * 0.7 = 36)
- executor.instances * executor.cores <= spark可分配的cpu核数 * 0.7(例如: 32核 * 0.7 = 22)
- cores.max = executor.instances * executor.cores
默认情况下,executor.memory 配置为8G,除非总的内存比8G还小,根据上面策略,其它选项配置如下
- executor.instances = spark可分配的内存数 * 0.7 / executor.memory = 52 * 0.7 / 8 = 4
- executor.cores = spark可分配的cpu核数 * 0.7 / executor.instances = 32 * 0.7 / 4 = 5
- cores.max = executor.instances * executor.cores = 4 * 5 = 20
| 注意 |
|---|
给引擎分配的cpu个数、内存大小,不能超过spark服务器拥有的cpu个数、总内存的大小,否则引擎会启动失败。 |
第二步:数据挖掘服务引擎连接测试:
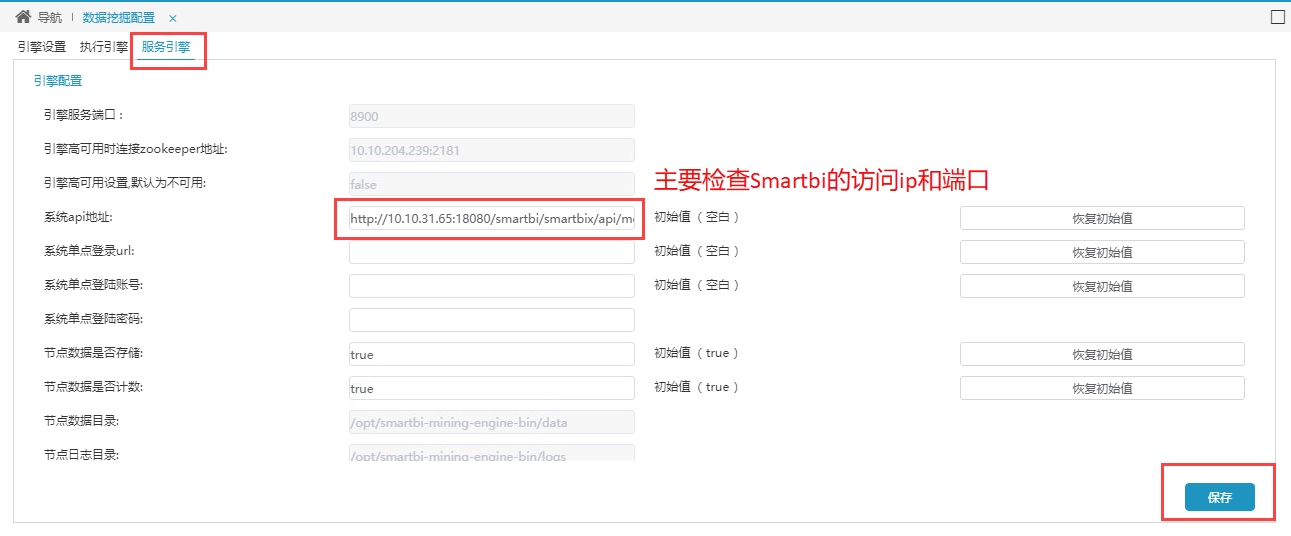
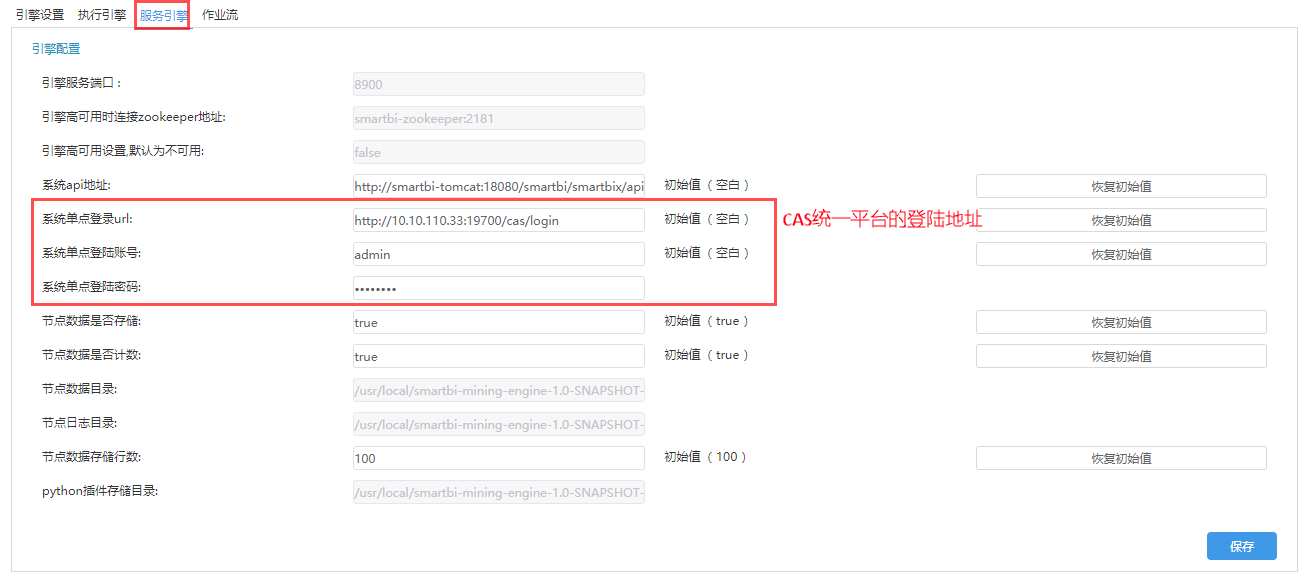
(1)打开服务引擎--引擎配置,如下图所示(具体配置根据实际部署环境修改):
| 注意 | |||||||
|---|---|---|---|---|---|---|---|
如果Smartbi配置了如果Smartbi版本为v9.5且配置了CAS单点登录,如下图所示(具体配置根据实际部署环境修改):
|
(2)执行引擎和服务引擎完成设置、保存后回到引擎设置,对引擎地址、服务地址重新点击测试,弹出平台和引擎双向连通,说明设置成功,进行保存。如下图所示。
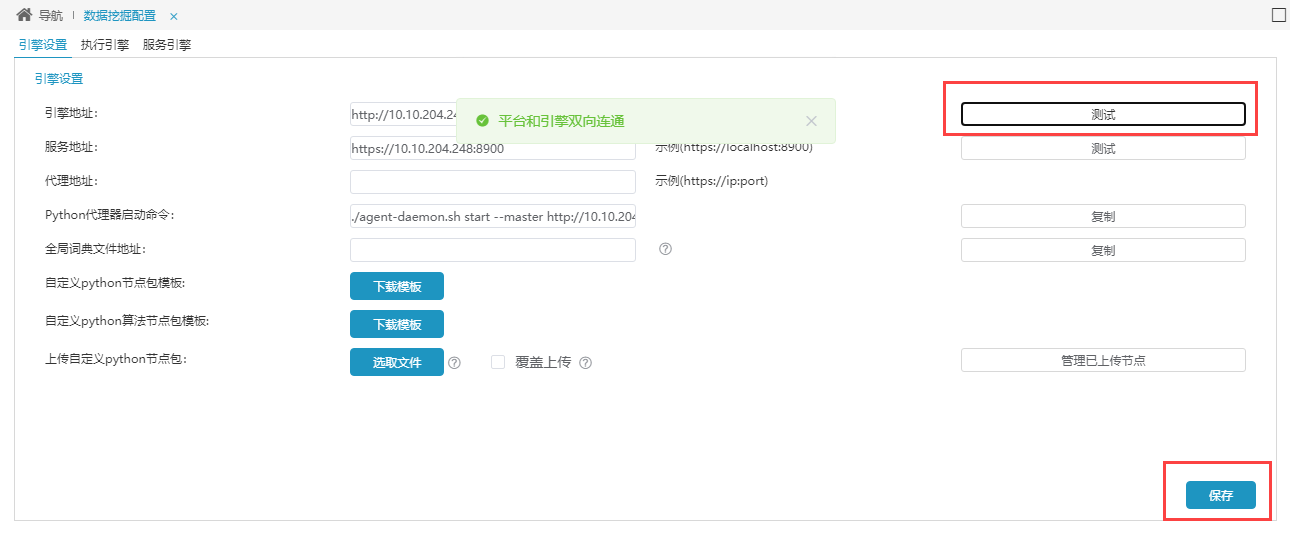
2.5 运维操作
1、启动/重启/查看执行引擎
| 代码块 | ||||
|---|---|---|---|---|
| ||||
cd /opt/smartbi-mining-engine-bin/engine/sbin ./experiment-daemon.sh restart #重启实验引擎 ./experiment-daemon.sh stop #停止实验引擎 ./experiment-daemon.sh status #查看实验引擎运行状态 ./service-daemon.sh restart #重启服务引擎 ./service-daemon.sh stop #停止服务引擎 ./service-daemon.sh status #查看服务引擎运行状态 |
2、测试执行引擎
参考 试数据挖掘集群及其组件
3、日志查看
数据挖掘的日志路径:/opt/smartbi-mining-engine-bin/logs
安装部署或者使用中有问题,可能需要根据日志来分析解决。
4、设置数据挖掘开机启动
进入/etc/init.d目录,创建数据挖掘-实验引擎启动配置文件
| 代码块 | ||
|---|---|---|
| ||
vi /etc/init.d/mining-engine |
配置参考如下:
| 代码块 | ||||
|---|---|---|---|---|
| ||||
#!/bin/bash
#
# tomcat startup script for the mining-engine server
# chkconfig: 345 80 20
# description: start the mining-engine deamon
#
# Source function library
. /etc/rc.d/init.d/functions
prog=mining-engine
JAVA_HOME=/home/smartbi/jdk1.8.0_181/ #注意替换成实际的JAVA部署路径
export JAVA_HOME
CATALANA_HOME=/data/smartbi-mining-engine-bin/engine/ #注意替换成实际的数据挖掘部署路径
export CATALINA_HOME
case "$1" in
start)
echo "Starting mining-service..."
$CATALANA_HOME/sbin/experiment-daemon.sh start
;;
stop)
echo "Stopping mining-service..."
$CATALANA_HOME/sbin/experiment-daemon.sh stop
;;
restart)
echo "Stopping mining-service..."
$CATALANA_HOME/sbin/experiment-daemon.sh stop
sleep 2
echo
echo "Starting mining-service..."
$CATALANA_HOME/sbin/experiment-daemon.sh start
;;
*)
echo "Usage: $prog {start|stop|restart}"
;;
esac
exit 0 |
进入/etc/init.d目录,创建数据挖掘-服务引擎启动配置文件
| 代码块 | ||
|---|---|---|
| ||
vi /etc/init.d/mining-service |
配置参考如下:
| 代码块 | ||||
|---|---|---|---|---|
| ||||
#!/bin/bash
#
# tomcat startup script for the mining-service server
# chkconfig: 345 80 20
# description: start the mining-service deamon
#
# Source function library
. /etc/rc.d/init.d/functions
prog=mining-service
JAVA_HOME=/home/smartbi/jdk1.8.0_181/ #注意替换成实际的JAVA部署路径
export JAVA_HOME
CATALANA_HOME=/data/smartbi-mining-engine-bin/engine/ #注意替换成实际的数据挖掘部署路径
export CATALINA_HOME
case "$1" in
start)
echo "Starting mining-service..."
$CATALANA_HOME/sbin/service-daemon.sh start
;;
stop)
echo "Stopping mining-service..."
$CATALANA_HOME/sbin/service-daemon.sh stop
;;
restart)
echo "Stopping mining-service..."
$CATALANA_HOME/sbin/service-daemon.sh stop
sleep 2
echo
echo "Starting mining-service..."
$CATALANA_HOME/sbin/service-daemon.sh start
;;
*)
echo "Usage: $prog {start|stop|restart}"
;;
esac
exit 0 |
设置开机启动
| 代码块 | ||
|---|---|---|
| ||
chmod +x /etc/init.d/mining-engine #添加执行权限 chmod +x /etc/init.d/mining-service #添加执行权限 chkconfig mining-engine on #添加到开机启动 chkconfig mining-service on #添加到开机启动 chkconfig --list #查看开机启动服务列表 |


