实施过程
本案例数据集来源于kaggle赛题数据,共计15万条客户数据,包括信用客户和逾期客户,并对数据进行人工标注,标注分为两类,分别为:0(信用客户)和1(逾期客户)。字段说明见表2-1。
表2-1 字段说明
字段名称 | 类型 | 字段说明 |
|---|---|---|
SeriousDlqin2yrs | 整型 | 好坏客户。取值为{0,1} |
RevolvingUtilizationOfUnsecuredLines | 浮点型 | 可用额度比值 |
age | 整型 | 年龄 |
NumberOfTime30-59DaysPastDueNotWorse | 整型 | 逾期30-59天笔数 |
DebtRatio | 浮点型 | 负债率 |
MonthlyIncome | 整型 | 月收入 |
NumberOfOpenCreditLinesAndLoans | 整型 | 信贷数量 |
NumberOfTimes90DaysLate | 整型 | 逾期90天笔数 |
NumberRealEstateLoansOrLines | 整型 | 固定资产贷款量 |
NumberOfTime60-89DaysPastDueNotWorse | 整型 | 逾期60-89天笔数 |
NumberOfDependents | 整型 | 家属数量 |
数据接入
在实验中添加数据源节点,将评分卡客户数据读取进来,部分数据如图所示:

为了方便理解本数据集每个特征的含义,使用元数据编辑节点,添加中文字段别名,更改后的输出如图所示:

流程图如图:

数据探索
本案例的探索分析是对数据进行缺失值、重复值与异常值分析,分析出数据的规律以及异常值。
为了查看整体数据集数值型数据的情况,我们接入一个全表统计节点,选中所有数值型字段如图:

输出结果如图,可以看到部分数据(月收入、家属数量)存在缺失值。可以看到“月收入”缺失达到近20%,“家属数量”缺失较少仅有2.6%的缺失。

为了统计所有数据中好坏客户的分布情况,选择聚合节点,选择分组计数,如图:

输出结果好坏客户分布情况图如下,发现0类样本占有较大的比例,则需要考虑到样本不平衡问题。

通过全表统计节点查看所有数据的分布情况,查看各指标的直方图、箱线图分布情况,如图所示。发现“年龄”的最小值居然是0,但是根据我们的常识,小于18岁是不能在银行办理信用卡或是贷款业务的。以及看到三个逾期天数指标(逾期30-59天、逾期60-80天,逾期90天)是存在比较严重的离群值的。




图2-8 直方图、箱线图
数据预处理
通过数据探索发现,月收入、家属数量这两个字段数据有部分空值、三个逾期天数指标存在异常值和部分数据可能有重复值。以及好坏客户的数据比例存在明显的不平衡现象,如果将这些数据直接进入模型,必然会对分析造成很大的影响,得到的结果的质量也必然是存在问题的。那么,在利用到数据之前就必须先进行数据预处理,把无价值的指标及数据去除。
1、去重复值
通过去除重复值节点将重复行的数据进行给去除,去除后结果如图:
2、空值处理
由于“家属数量”缺失较少,可直接使用中位数进行填充。“月收入”这个特征对于征信来说非常重要的,本案例采用随机森林填补法来填充,即将缺失的特征值作为预测值,将未缺失的“月收入”数据作为训练样本的标签。流程图如下:

3、异常值处理
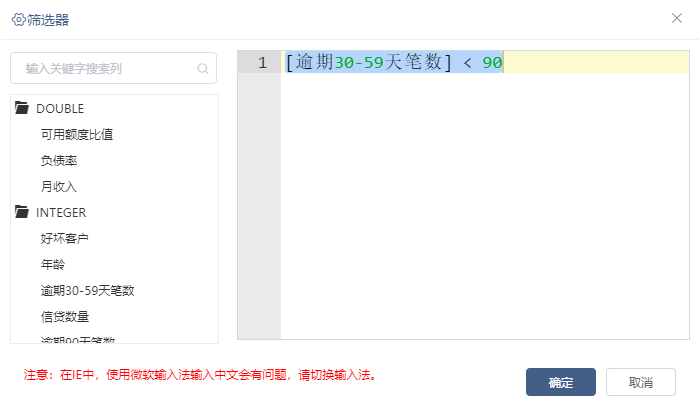
根据探索分析发现年龄的最小值为0,通常我们知道年龄小于18岁是不能办理银行信用卡或者贷款业务的,并且发现三个逾期天数指标(逾期30-59天、逾期60-80天,逾期90天)是存在比较严重的离群值的。通过行选择节点筛选出年龄<18的数据分析发现仅有年龄=0的这一条数据,如图:

因此需要将年龄为0的数据进行删除过滤。

通过行选择节点筛选出发现三个逾期指标出现的情况发生在相同的行,维度都是(225,11)。因此将其中一个异常指标过滤删除即可:
4、处理样本不平衡
通过好坏客户分布情况图发现,0:1=139974:10026,是存在严重的样本不平衡的。这是在金融风控中非常常见的,因为会存在严重违约的用户毕竟是少数。本案例采取SMOTE上采样的方法处理数据不平衡。通过python脚本进行编写,核心代码如图所示:

处理不平衡数据后通过聚合节点分析发现1类和0类数据达到平衡状态,如图:

5、数据离散化
在建立模型前,需要对连续变量离散化,特征离散化后,模型会更稳定,降低了模型过拟合的风险。连续变量是在任意两个值之间具有无限个值的数值变量。连续变量可以是数值变量,也可以是日期/时间变量。例如,零件的长度,或者收到付款的日期和时间。因此,我们自定义离散操作如图所示:

整个的数据预处理流程如下:

特征选择
1、相关性分析
相关性分析是用来反映变量之间的相关关系的密切程度。相关系数的取值一般介于-1和1之间。当相关系数为正的时候,意味着变量之间是正相关的;当相关系数为负的时候,意味着变量之间是负相关的。我们选择相关性节点探索各指标的相关性,如图所示:

因此我们选择相关性较强的特征,如图:

模型建立
本案例采取逻辑回归模型,整体的流程图如图所示。
逻辑回归具有以下优势:
1、逻辑回归经过信贷历史的反复验证是有效的;
2、模型比较稳定相对成熟;
3、建模过程透明而不是黑箱;
4、不太容易过拟合。

通常而言,评分卡模型一般采用roc或ks曲线来评价模型的好坏。本案例的评估结果如图所示,发现该模型的auc取值为0.835,ks的最大取值为0.51,说明该模型的效果是不错的。



计算评分
1、模型系数
通过逻辑回归模型训练后接入模型系数节点,输出的模型系数如图:

2、计算得分
我们需要将逻辑回归转换为对应的分数,(0-999分)。
根据资料查得:Score = offset + factor * log(odds)

首先,我们得计算各特征的分数得分,部分核心代码如图所示:

各分数得分输出日志中可打印输出。

然后根据基础分值与各特征的得分进行相加减获取最终信用评分,部分核心代码如图所示:
最后输出各特征指标的得分,根据得分结果可查看分析出评分越高的客户违约风险就越大。为此可对相应的工作采取措施。

总结
本章结合信用卡评分的案例,重点介绍了数据挖掘算法中逻辑回归分类算法在实际案例中的应用。本案例研究客户信用问题,从分析出客户的信用分值中可挖掘出该客户的违约风险程度,并针对违约客户的这些客群中采取相应的措施。


