+【数据挖掘】引擎调度机制执行粒度细化至单个节点
背景介绍
目前引擎调度策略是把实验作为整体进行调度,实验中的节点无法脱离出来独立执行。若引擎能够按照节点粒度进行调度,这样会给引擎在功能和扩展性方面带来好处。
功能简介
新版本,引擎按照节点粒度进行调度,可以带来以下几点优势:
- 可以做到断点续跑,如果在数据量大的情况下,会节省很大时间,提高实验的效率;
- 能单独执行一个节点,在实验的设计跟调式阶段带来很大便利;
- 可以对单节点进行资源控制,防止某个节点占用资源太大,对其它节点造成影响;
- 调度更加灵活,同个实验中的不同节点,可以在不同机器中执行;
- 部署架构扩张性更好,可以横向扩张节点的执行机器。
具体在 Smartbi上体现为节点的右键菜单增加“执行该节点”和“从当前节点开始执行”功能项。
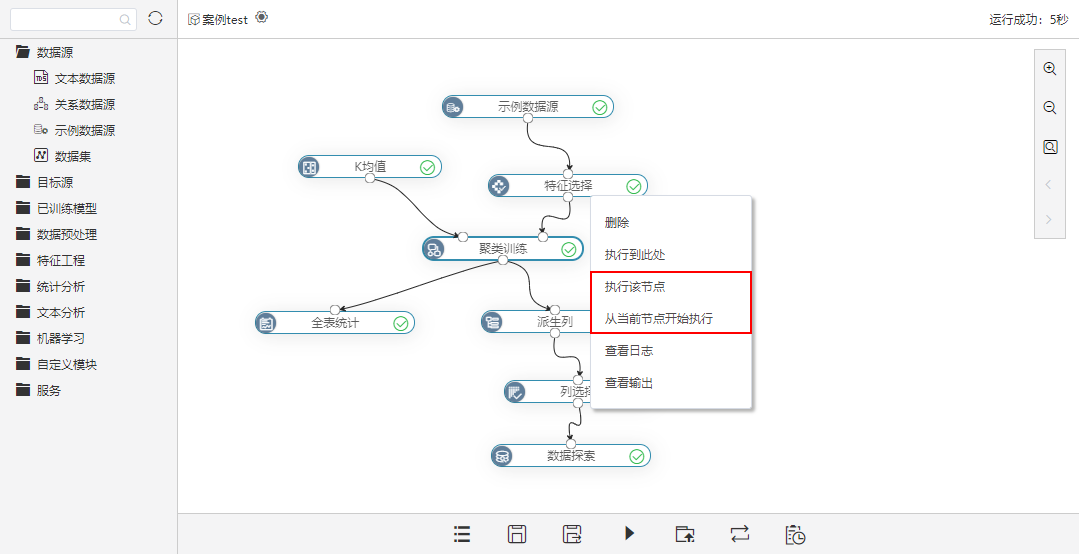
详情参考
关于“执行该节点”和“从当前节点开始执行”功能项,详情请参考 实验界面介绍 。
+【数据挖掘】数据预处理新增异常值处理节点
背景介绍
无论是机器学习还是数据分析,总是要面对一大堆数据,总是免不了出现异常值的可能性,,异常值可以大幅度地改变数据分析和统计建模的结果,可能会造成回归、方差分析等统计模型假设的基本假设受影响等问题。
功能简介
新版本新增异常值处理节点,可对存在异常的数据进行检测和识别,且对识别出的异常值进行处理。
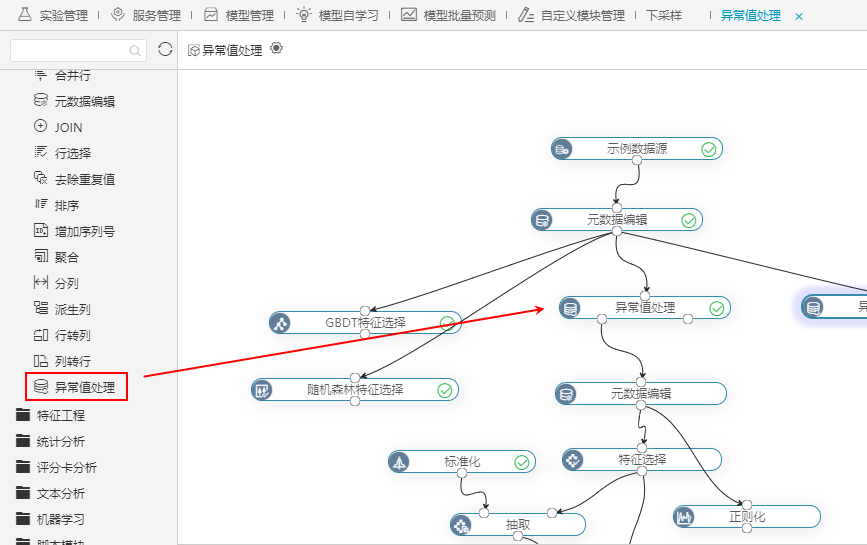
详情参考
关于数据挖掘的异常值处理,详情请参考数据挖掘-异常值处理。
+【数据挖掘】统计分析增加RFM节点
背景介绍
RFM模型是衡量客户价值和客户创利能力的重要工具和手段。在众多的客户关系管理(CRM)的分析模式中,RFM模型是被广泛提到的。因此Smartbi在新版本新增RFM节点,为更多的营销决策提供支持。
功能简介
RFM节点通过对选择的特征列按照阈值进行二分(可按均值、指定值、中值),将客户数据划分为不同的客群。新版本,左侧资源树统计分析节点下新增RFM节点。
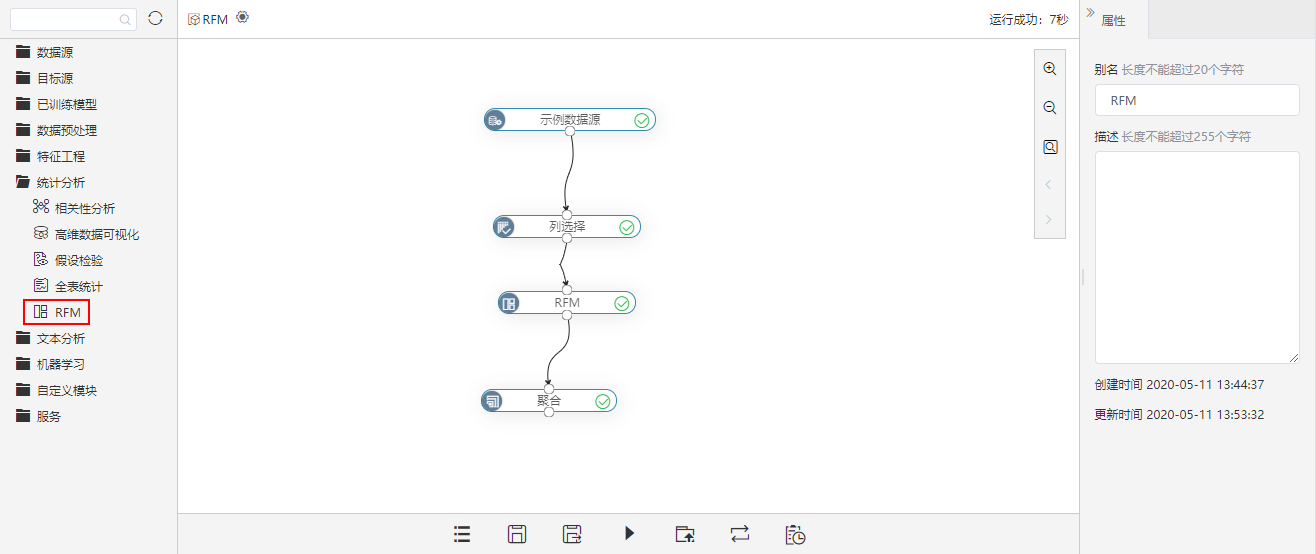
详情参考
详情参考数据挖掘-RFM。
+【数据挖掘】评分卡分析新增WOE编码节点
背景介绍
评分卡是将模型变量WOE编码方式离散化之后运用logistic回归模型进行的一种二分类变量的广义线性模型,也是信用风险评估和互联网金融领域常用的建模方法,比如信用卡风险评估、贷款发放等业务。除此之外,在其它领域也能够看到评分卡被用来作为分数评估,比如常见的客服质量打分、芝麻信用分打分等。
功能简介
WOE则是对原始自变量的一种编码形式,要对一个变量进行WOE编码,需要首先把这个变量进行分组处理,之后再计算出WOE值和IV值,根据这两个值来判断变量的预测强度。
因此新版本新增WOE编码节点,可以对字段分箱后计算WOE值和IV值。
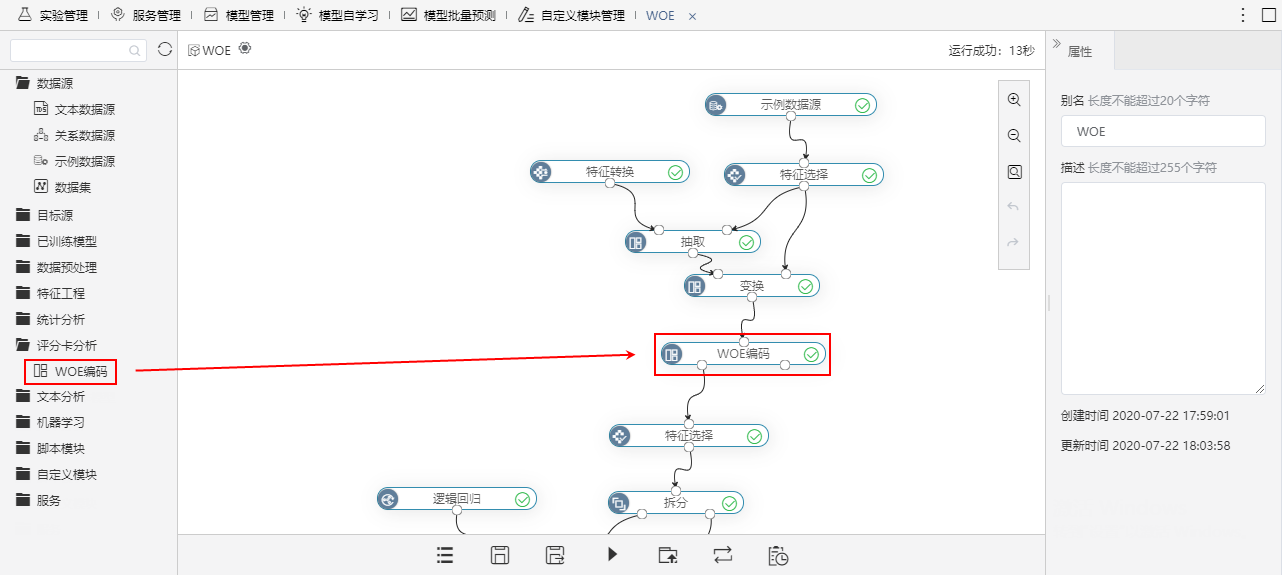
在查看分析结果中记录了变量的IV值,分箱区间及每个区间的WOE值。
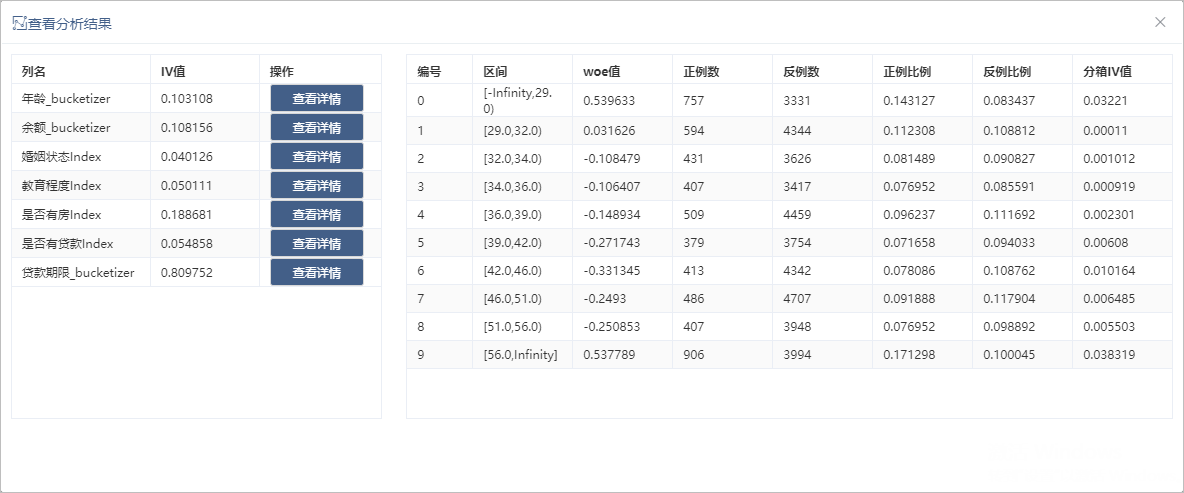
详情参考
关于WOE编码,详情请参考 数据挖掘-WOE编码。
+【数据挖掘】文本分析增加主题分析功能
背景介绍
LDA可以用于从海量的文本中,根据统计模型,自动提取出由关键词组成的热门主题,让我们快速知道,这些大量无规则的文本中,主要讲述了什么内容。业务人员在商业分析的过程中也是离不开海量的文本数据,如果将基于LDA的主题分析应用在商业分析上,那么将会给业务人员带来极大的方便。
功能简介
LDA主题模型主要用来推测文档的主题分布,它可以将文档集中每篇文档的主题以概率分布的形式给出,从而通过分析一些文档抽取出它们的主题分布后,便可以根据主题分布进行主题聚类或文本分类。 新版本,左侧资源树文本分析节点下新增LDA和主题-词分布(LDA)节点。
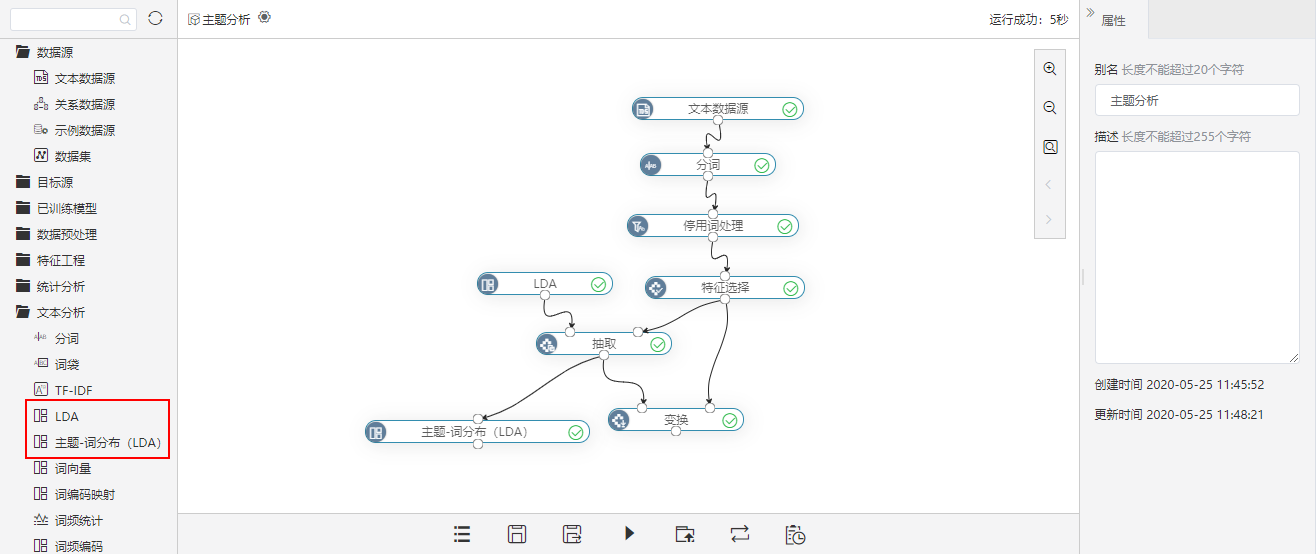
详情参考
关于LDA和主题-词分布(LDA)节点的功能,详情参考LDA、数据挖掘-主题-词分布(LDA)。
+【数据挖掘】多分类算法新增多层感知机节点
背景介绍
数据中潜藏的规律按照以往的聚类,回归等传统分析手段很难被发现,Smartbi Mining新增多层感知机算法节点。多层感知机(MLP,Multilayer Perceptron)也叫人工神经网络(ANN,Artificial Neural Network),通过神经网络中的节点和隐藏层对数据特征进行‘学习’,并以模型形式保存,用于分类、预测等使用场景。
功能简介
多层感知机作为多分类算法节点与其他机器学习节点同样使用。

详情参考
关于数据挖掘的多层感知机,详情请参考 多层感知机。
+【数据挖掘】关联规则支持输出频繁项集及其支持度
背景介绍
Smartbi现有的FP-Growth算法输出的是模型根据关联规则推荐的预测结果,在实际应用中,也希望输出对算法挖掘出的关联规则及其支持度,通过这些信息能够发现隐藏在数据集中的有意义的联系。因此在新版本,关联规则支持输出算法挖掘出的频繁项集以及对应的前项、后项。
功能简介
“模型系数”节点支持输出所有频繁项集,以及所有频繁项集的频率和支持度。
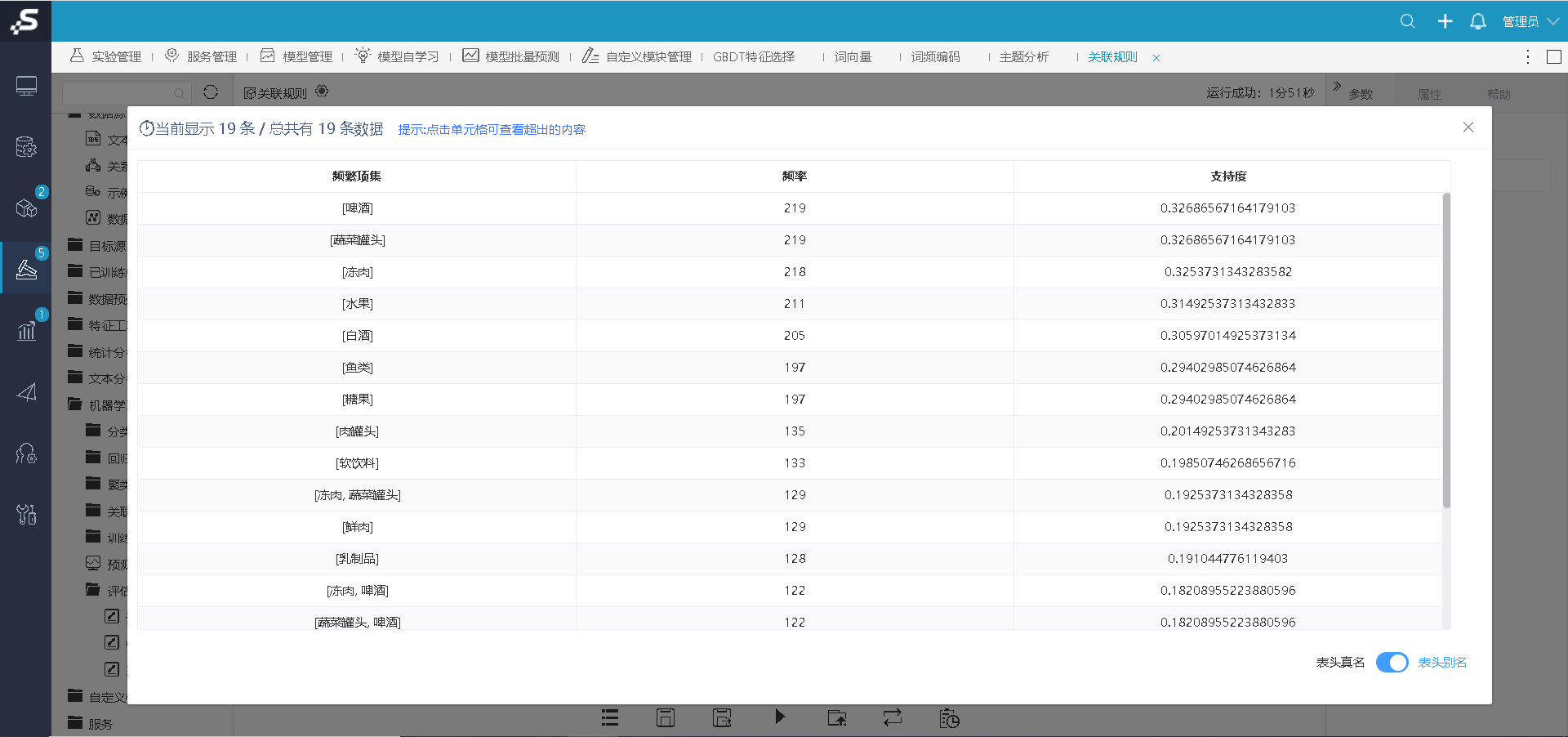
详情参考
关于FP-Growth算法,请参考 数据挖掘-FP-Growth。
+【数据挖掘】数据集新增新建、编辑数据集入口
背景介绍
目前Smartbi的挖掘模块中,数据集节点只有选择数据集功能,为了方便用户可以在挖掘的实验界面中新建和编辑数据集,新版本新增了新建、编辑数据集的入口。
功能简介
新版本在数据集节点的参数设置界面新增了新建、编辑数据集的入口。

关于数据源的数据集,详情请参考 数据集。
+【数据挖掘】机器学习新增关联规则生成节点,用于呈现关联规则常见指标
背景介绍
随着数据爆炸式增长,如何从海量数据中快速的挖掘出有用信息是当今社会亟待解决的问题。新版本的新增关联规则生成节点,支持输出更多关联规则的指标(置信度、提升度等),同时能自由筛选出多对多、多对一等不同关联形式,以此帮助用户快速生成关联规则、衡量其中的关联性,从海量数据中挖掘出有价值的数据,助力企业做出科学决策。
功能简介
新版本中,数据挖掘中新增关联规则生成节点,用于呈现关联规则常见的一些指标。
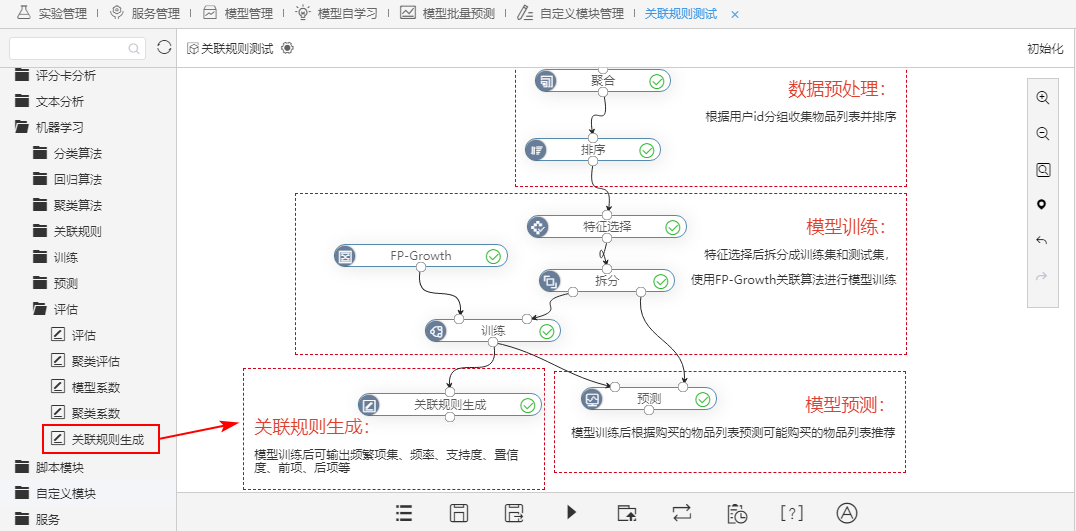
基于 FP-Growth 训练后的模型输入后,关联规则生成节点能够输出:频繁项集、支持度、置信度和提升度等指标。其中输出的前、后项个数,可便于筛选一对一、一对多、多对一、多对多等形式的关联规则。
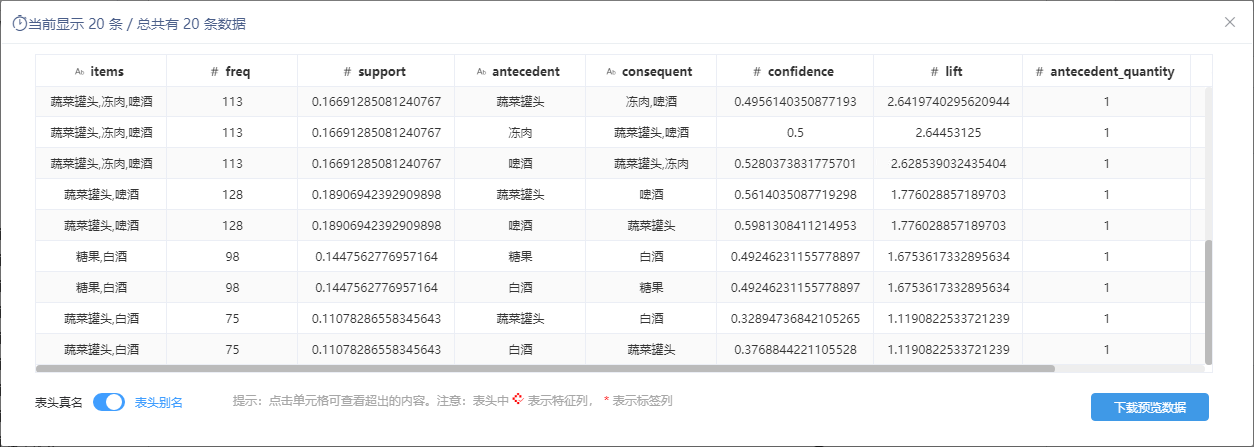
参考文档
关于关联规则功能,详情请参考 数据挖掘-关联规则生成 。
+【数据挖掘】支持在界面上传自定义Python节点
背景介绍
以前的版本,用户想要在产品中添加自定义的Python节点,需要在服务器上找到对应的路径再上传自定义Python节点包,操作繁琐。从提升用户体验感角度出发,产品支持在界面上上传自定义Python节点包,并且整合了系统中所有关于数据挖掘的配置项,提高了产品易用性。
功能简介
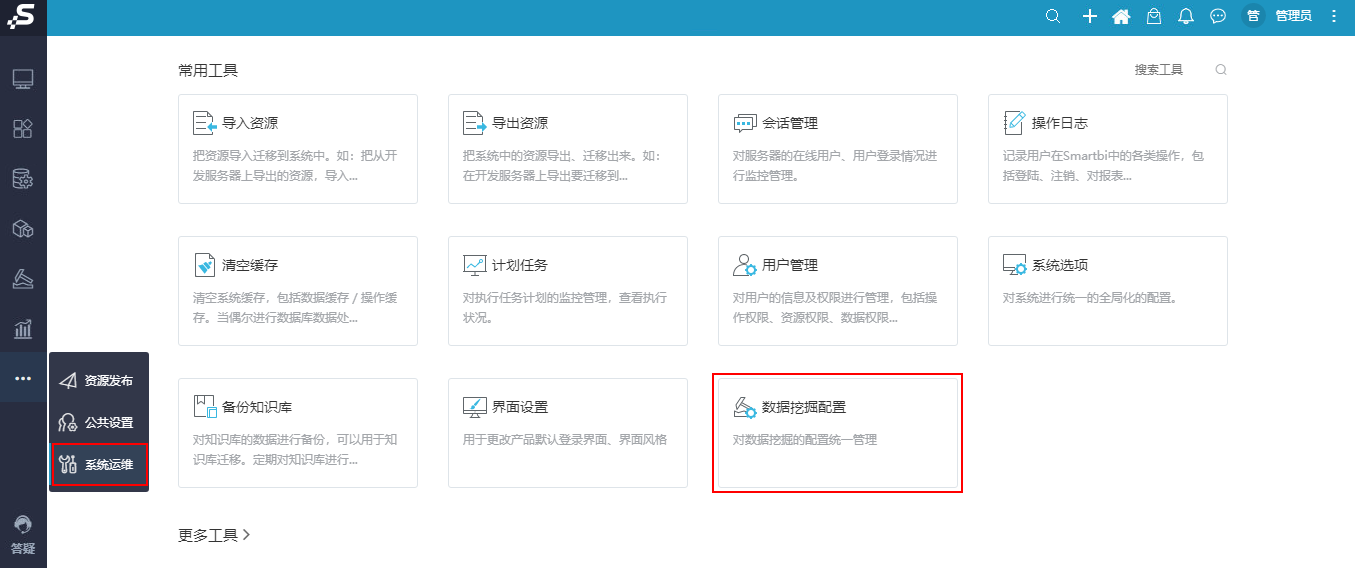
1、系统运维新增“数据挖掘配置”,用于将所有数据挖掘的相关配置统一管理。
2、用户可以在“数据挖掘配置”界面上,通过上传自定义Python节点包(按照模板格式编写)来添加自定义Python节点。
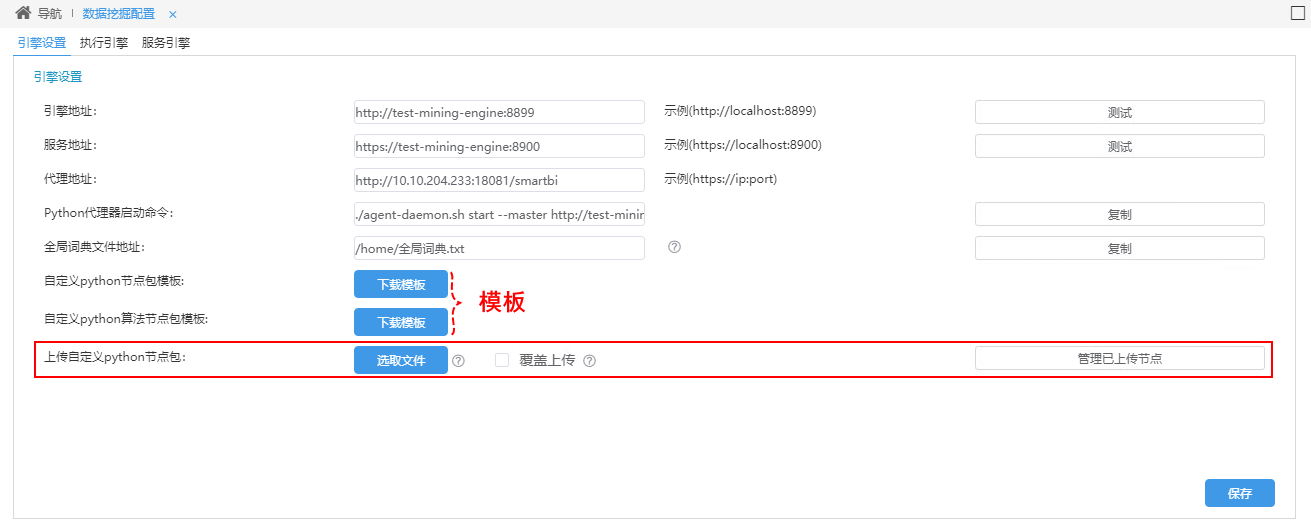
并可对已上传的自定义节点进行管理:

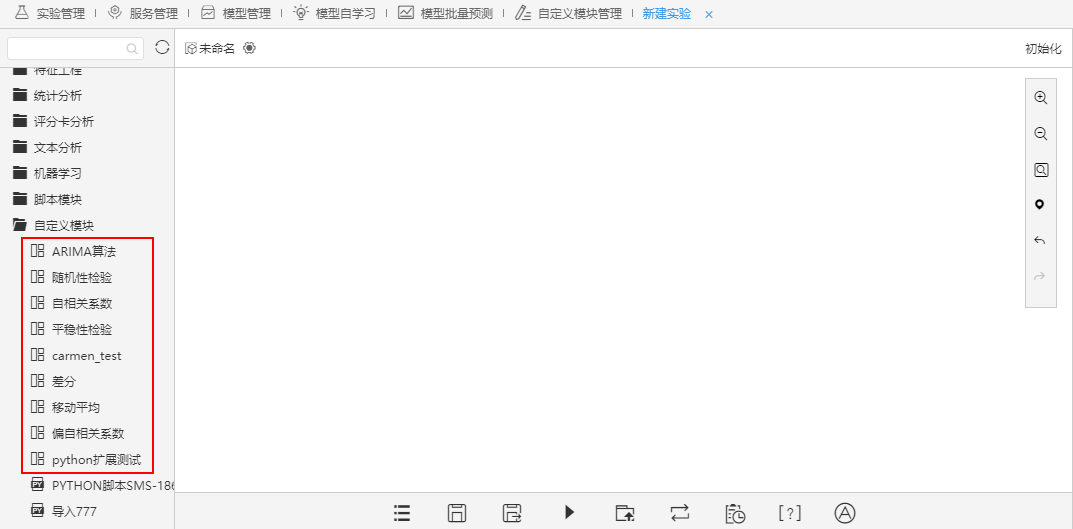
上传成功后刷新界面,上传的自定义节点会出现在节点资源树的自定义模块目录下(一次只能上传一个节点):
详情参考
关于数据挖掘配置,详情请参考 引擎设置 。
+【数据挖掘】数据集节点支持所有的Smartbi数据集
背景介绍
为了方便用户的使用,我们在数据挖掘的数据源中新增数据集节点,支持所有的Smartbi数据集,用户可以使用已经建好的数据集进行数据挖掘,丰富了输入数据的来源,减少了用户操作。
功能简介
数据集节点支持所有Smartbi数据集:



