本节介绍smartbi连接数据挖掘实验、服务引擎和Python计算机点以及测试服务是否正常运行。
1、测试数据挖掘实验引擎
1.检查smartbi连接数据挖掘引擎配置
①登录smartbi,检查当前连接的数据挖掘引擎配置
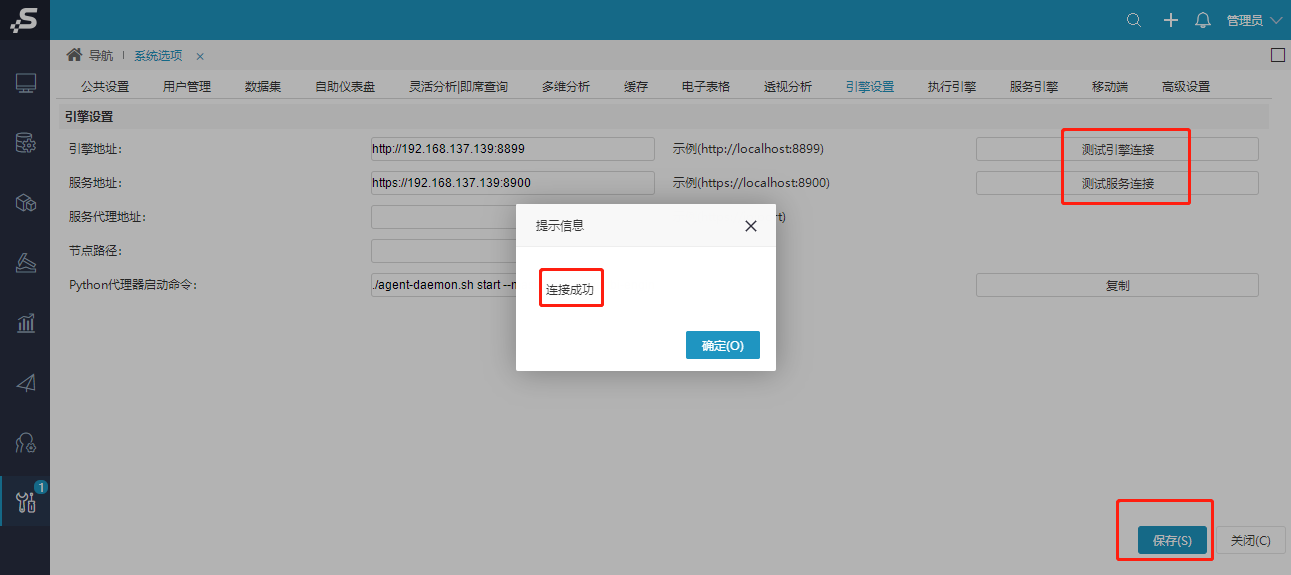
系统运维--系统选项—引擎设置,如图所示,实验引擎和服务引擎连接地址无误后,点击测试连接,均能提示连接成功。
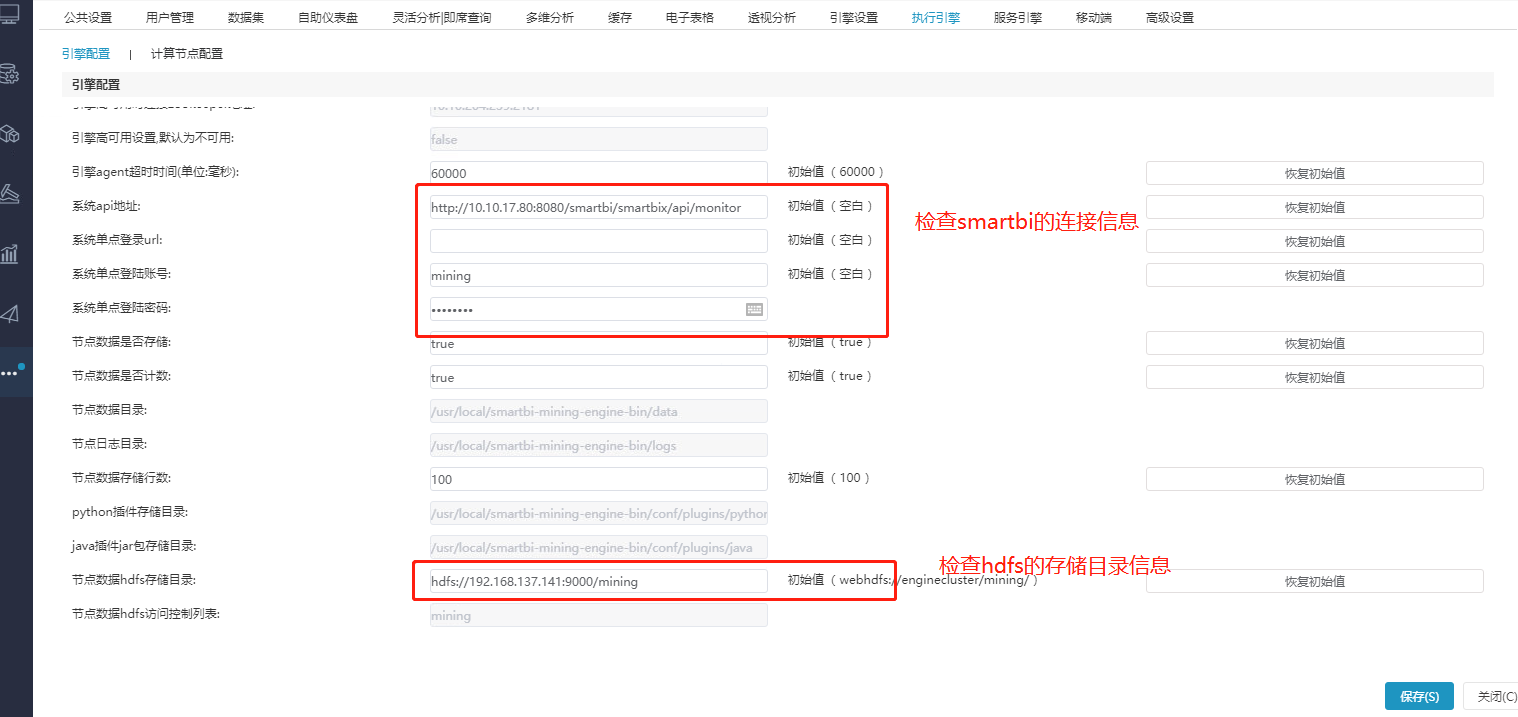
②系统运维–系统选项–执行引擎–引擎配置,检查配置,确认连接信息
③系统运维–系统选项–执行引擎–计算节点,检查配置,确认连接信息
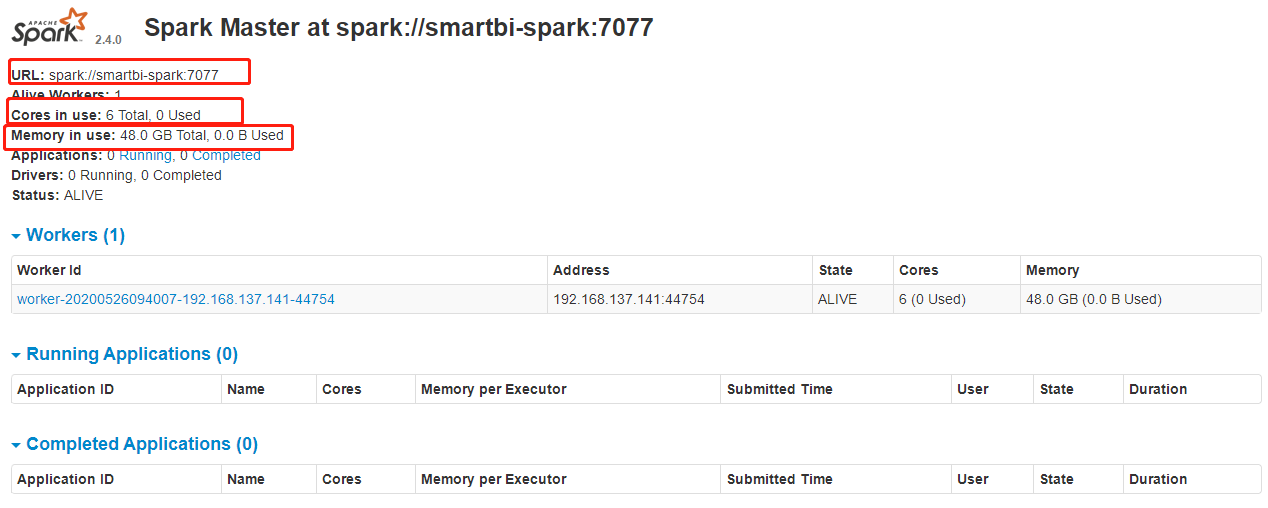
浏览器访问spark master webui, 访问地址:http://sparkmaster安装机器ip:8080, 比如spark master安装在192.168.137.141机器,那访问地址就是: http://192.168.137.141:8080
访问后,显示如下,第一个框是指spark master连接地址,第二个框是指spark可分配的cpu核数,第三个框指spark可分配的内存数。
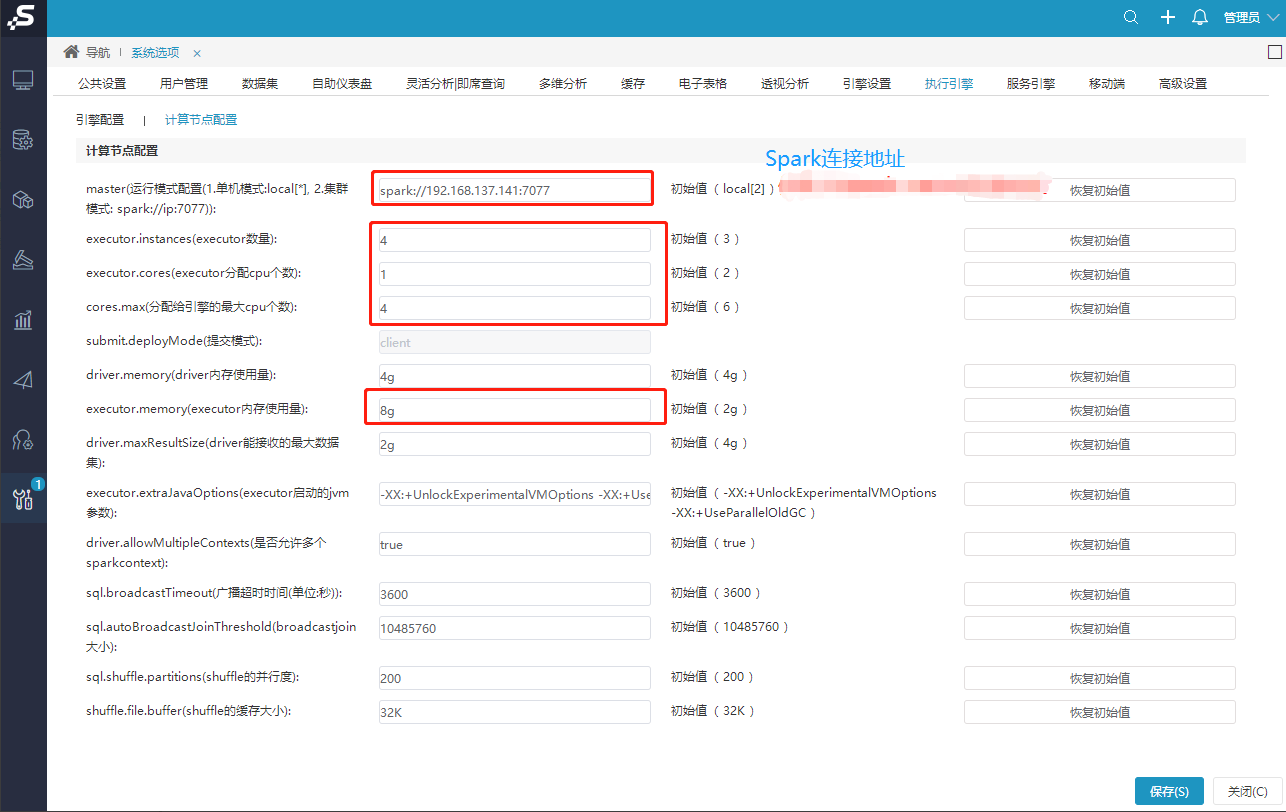
系统运维—系统选项—执行引擎—计算节点配置
如下图所示,重点配置红框地方,第一个框填写spark master连接地址,其它选项配置策略推荐如下(某种场景下,这并不是最优策略,可根据实际情况调整):
Spark配置解析
1.executor.instances * executor.memory <= spark可分配的内存数 * 0.75(例如上图: 48G * 0.75 = 36)
2.executor.instances * executor.cores <= spark可分配的cpu核数 * 0.75(例如上图: 6核 * 0.75 = 4)
3.cores.max = executor.instances * executor.cores
默认情况下,executor.memory 配置为8G,除非总的内存比8G还小,根据上面策略,其它选项配置如下
executor.instances = spark可分配的内存数 * 0.75 / executor.memory = 48 * 0.75 / 8 = 4
executor.cores = spark可分配的cpu核数 * 0.75 / executor.instances = 6 * 0.75 / 4 = 1
cores.max = executor.instances * executor.cores = 4 * 1 = 4
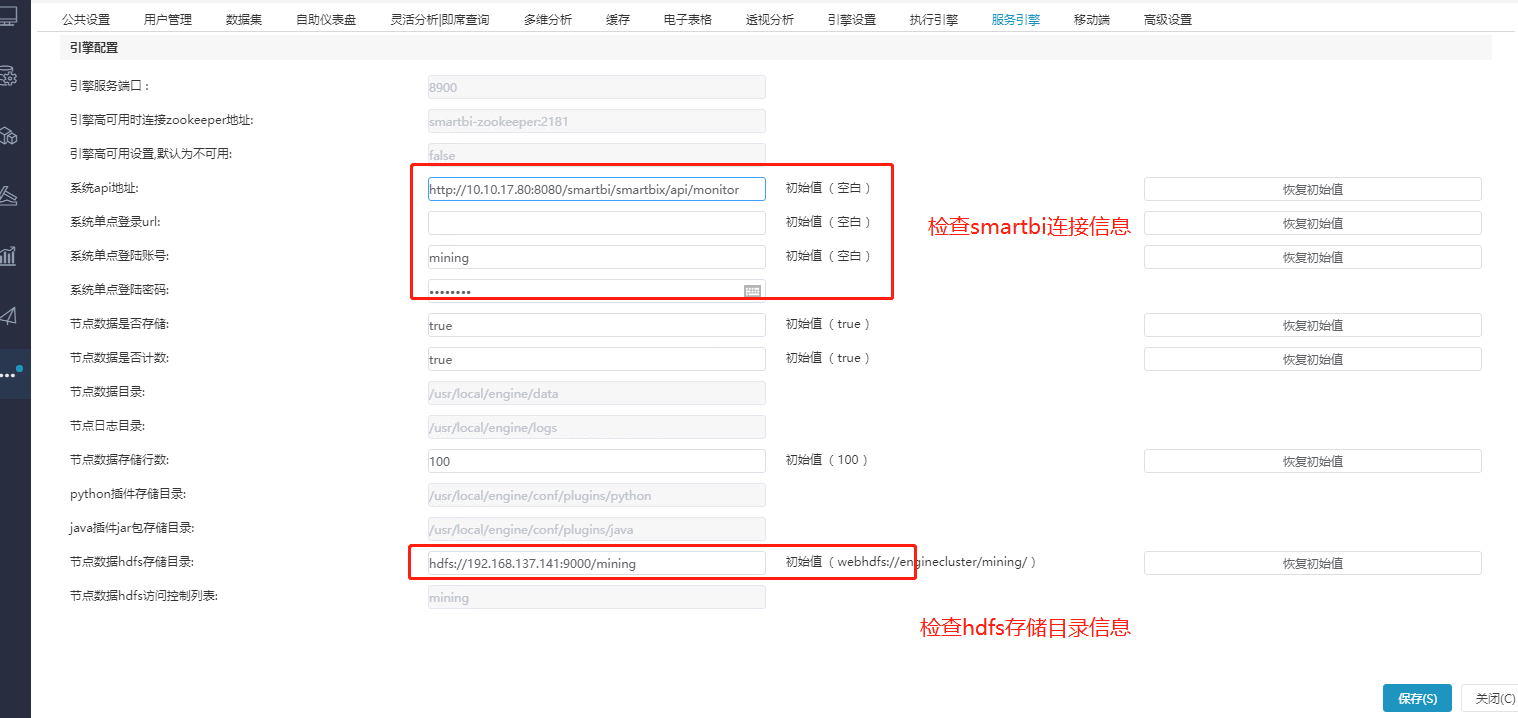
④系统运维–系统选项–服务引擎,检查配置,确认连接信息