回归算法常用于股票预测、房价预测等线性增长的问题场景。
梯度提升回归树
概述
梯度提升回归树是梯度提升树算法,原理是训练多棵回归树,每棵树建立是基于前一课树的残差,基函数为CART树,损失函数为平方损失函数的回归算法。
示例
使用“波士顿房价预测”案例数据,预测波士顿房价。

其中,相关性分析是为了分析特征变量与目标变量的相关性系数,方便特征选择进入模型训练。
梯度提升回归树参数如下:
参数名称 | 值 | 说明 |
|---|---|---|
归一化 | 正则化 | 详情请参考 归一化 介绍说明。 |
标准化 | ||
最小最大值归一化 | ||
最大绝对值归一化 | ||
分裂特征的数量 | 取值范围:>=2的整数; 默认值:32。 | 对连续类型特征进行离散时的分箱数; 该值越大,模型会计算更多连续型特征分裂点且会找到更好的分裂点,但同时也会增加模型的计算量; |
树的深度 | 取值范围:[1,30]的整数;默认值为4。 | 当模型达到该深度时停止分裂; 树的深度越大,模型训练的准确度更高,但同时也会增加模型的计算量且会导致过拟合; |
计算信息增益的方式 | gini | 裂分标准,Entropy表示熵值,Gini表示基尼指数; |
entropy |
线性回归
概述
一种常用的回归方法,它是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计方法,通过凸优化的方法进行求解,以达到预测评估的效果。
示例
使用“波士顿房价预测”案例数据,预测波士顿房价。
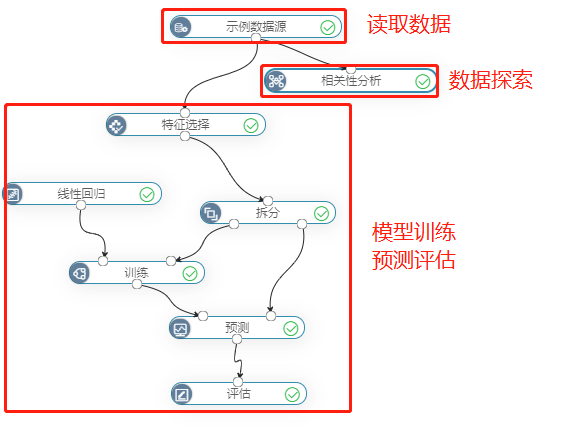
其中,相关性分析是为了分析特征变量与目标变量的相关性系数,方便特征选择进入模型训练。
线性回归的参数如下:
参数名称 | 值 | 说明 |
|---|---|---|
归一化 | 正则化 | 详情请参考 归一化 介绍说明。 |
标准化 | ||
最小最大值归一化 | ||
最大绝对值归一化 | ||
最大迭代数 | 参数范围为:>=0的整数,默认值为10 | 算法的最大迭代次数,达到最大迭代次数即退出。 最大迭代次数的值越大,模型训练更充分,但会耗费更多时间。 |
混合参数 | 参数范围为:[0,1]的数,默认值为0 | 控制惩罚类型,平方误差损失函数中的 ρ,参数范围为:[0,1]的数。其中:0表示L2惩罚,1表示L1惩罚,0~1表示L1和L2惩罚的结合。 对模型系数惩罚(或称正则化)可减少模型过拟合。 |
正则参数 | 参数范围为:>=0的数,默认值为 :0。 | 正则项系数,损失函数中的 。 正则化可以解决模型训练中的过拟合现象; 正则项系数越大,模型越不会过拟合。 |
epsilon | 参数范围为:>1的数。默认值为1.35 | huber损失函数中的 δ ;调节损失函数,用于控制算法模型的健壮性; epsilon 越大,损失函数对异常点惩罚就越大,也就是对异常点越敏感; |
收敛阈值 | 参数范围为:>=0的数,默认值为 :0.000001。 | 收敛误差值。 收敛误差值,当损失函数取值优化到小于收敛阈值时停止迭代。 |
损失函数 | squaredError | 可待优化的损失函数,用于衡量模型的输出值和真实值之间的差距。 squaredError表示平方误差,huber表示平滑平均绝对误差。 |
huber |


