示例
使用“航空公司客户价值分析”案例数据,分析客户为高价值客户、一般客户、低价值客户。
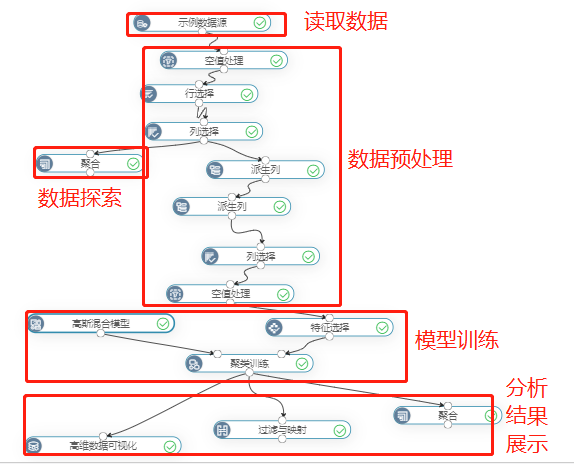
高斯混合模型参数如下:
参数名称 | 值 | 说明 |
|---|---|---|
归一化 | 正则化 | 详情请参考 归一化 介绍说明。 |
标准化 | ||
最小最大值归一化 | ||
最大绝对值归一化 | ||
K值 | 取值范围是:>=2的整数,默认值为2 | 期待将数据聚类的数目; |
收敛阈值 | 参数范围为:>=0的数,默认值为 :0.000001。 | 收敛误差值;当各类的聚类平方和小于收敛阈值时则停止迭代; |
迭代次数 | 参数范围:>=0的正整数,默认值为20。 | 算法的最大迭代次数,达到最大迭代次数即退出。 最大迭代次数的值越大,模型训练更充分,但会耗费更多时间。 |


