概述
频繁模式,是找出数据集中共现概率大于阈值的事务。用法跟分类算法类似,先根据训练集,训练出所有的频繁项,在对测试集进行频繁项预测。
示例
使用“购物篮分析”案例数据,预测用户购买了物品1可能会购买物品2的可能性。
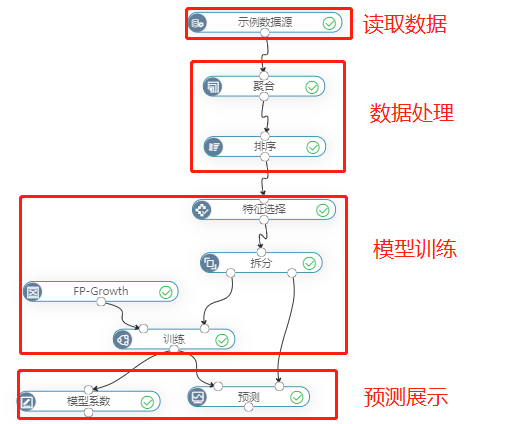
FP-Growth参数如下:
参数名称 | 值 | 说明 |
|---|---|---|
最小支持度 | 参数范围:[0,1]的小数,默认值为0.01 | 支持度,代表项集的频繁程度;最小支持度作为支持度的阈值,满足最小支持度的项集才会输出; |
最小置信度 | 参数范围:[0,1]的小数,默认值为0.01 | 置信度,代表包含A事务中同时包含B事务的频繁程度;最小置信度作为置信度的阈值,满足最小置信度的项集才会输出; |
例如:有以下项集
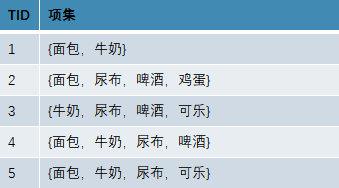
项集{牛奶,尿布,啤酒}的
1、支持度,
2、置信度,


