服务工作流示例
服务工作流是将数据挖掘以服务的方式进行发布。
要求:输入层必须是“服务输入”节点,输出层必须是“服务输出”节点。
通过部署服务后,通常用于数据预测的应用。“服务输入”的处理层可以实现数据来源于其它接口。
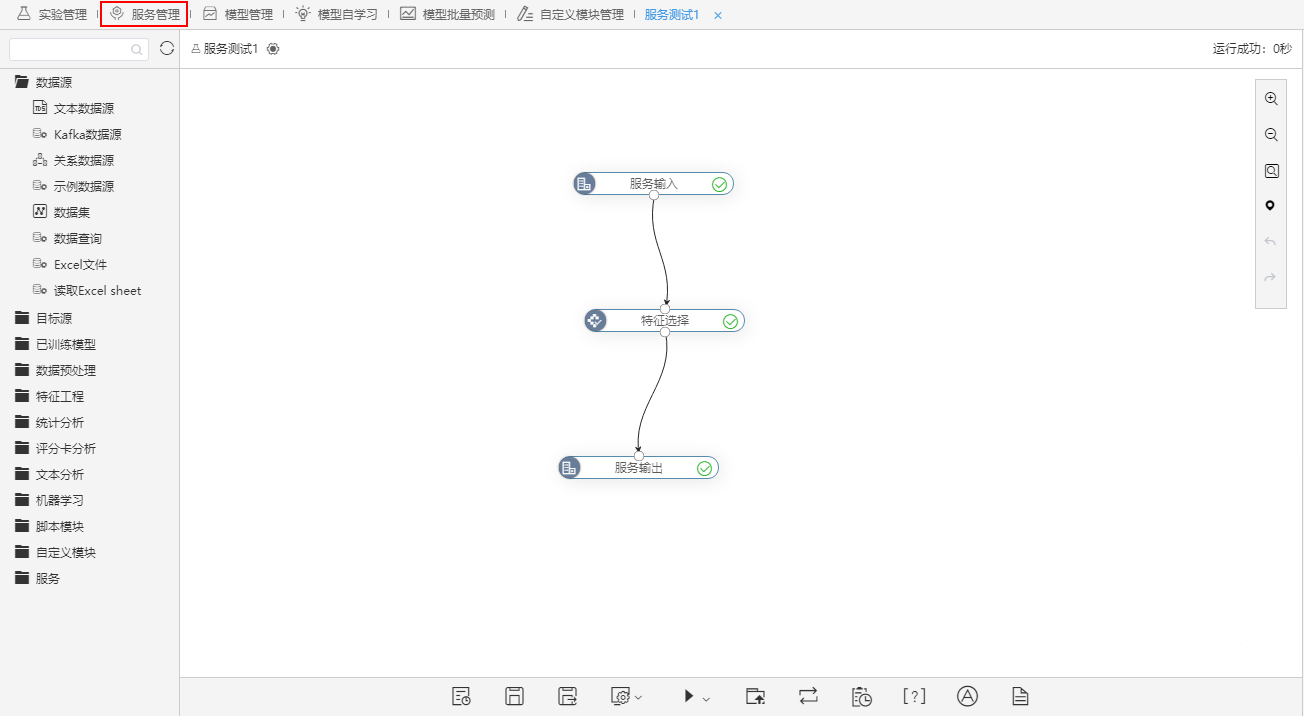
下图是一个简单的服务工作流示例:
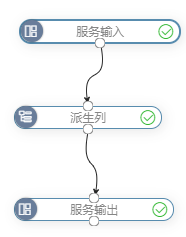
在这个工作流中,实现的是对输入的数据进行派生列处理后输出。
部署服务
概述
服务部署指的是当用户用实验训练好了一个预测模型 ,并将此预测模型部署成一个web的服务。当前发布的web服务就可以作为预测模型应用于类似场景的预测,当用户要预测一个新样本,只需要把样本特征信息用 restful api 传给服务,服务就可以依据训练好的预测模型返回预测结果。
前提条件:服务工作流完成搭建且执行成功。工作流中每个节点旁边显示绿色的勾即表示该节点是执行成功的。
部署方法
数据输入
服务输入中的数据支持“手工输入”和“选择节点数据”两种方式:
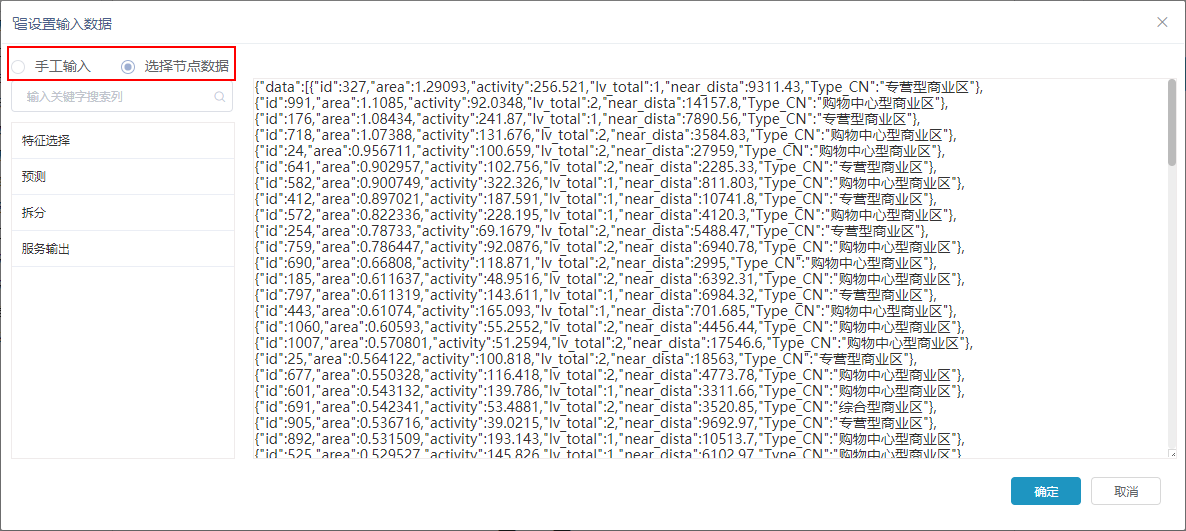
- 手工输入:是手工输入json列数据。
- 选择节点数据:是选择运行通过后的某节点输出结果数据。
部署方式
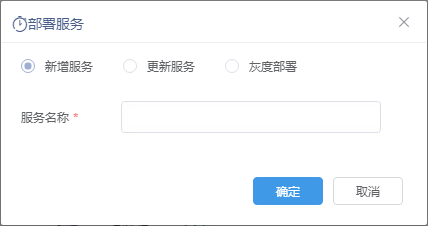
部署服务包括以下三种方式:
| 名称 | 说明 |
|---|---|
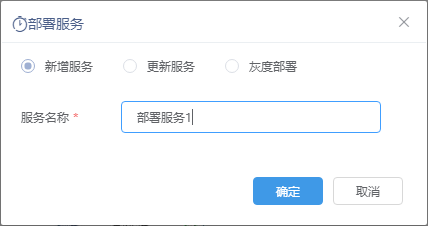
| 新增服务 | 输入服务名称新增一个服务:
一个服务实验可以生成多个服务。 |
| 更新服务 | 选择一个原服务更新其实验节点:
|
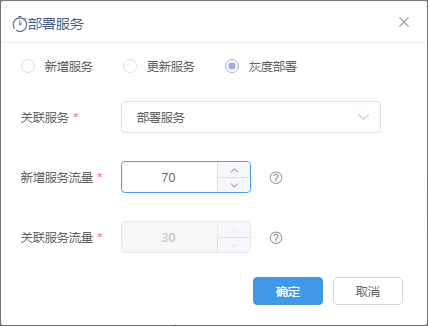
| 灰度部署 | 灰度部署用于使多版本模型并行运行,并保持多版本模型运行的结果,通过结果比较灰度测试的模型版本的准确性和稳定性。
灰度测试可以确保整个系统的稳定性,并且可以在初始灰度级找到并调整问题以确保其影响度。
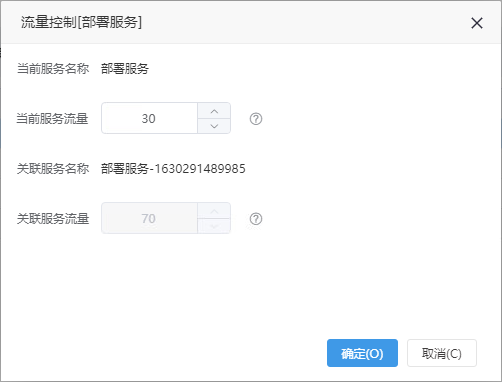
例如:A服务流量设置60,则B服务流量为40,将会有40%的概率调用B服务,将会有60%的概率执行A服务(主服务)。生成的B服务名称是以A服务名称加此时的时间戳,一个服务只能产生一个B服务。 在灰度部署中,已经生成过灰度服务的服务将不能被选择。
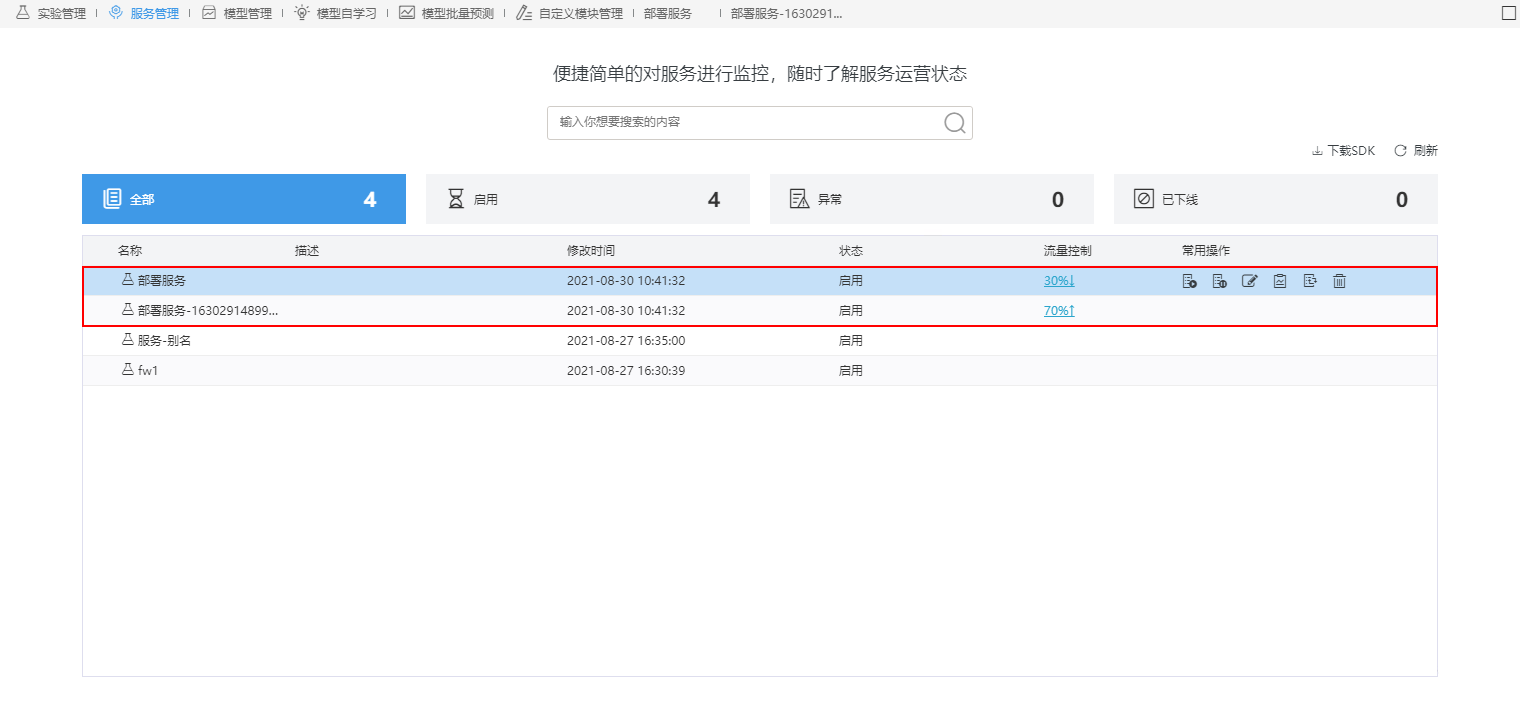
生成的服务将会在服务管理中显示,如图灰度部署生成两个服务,上面的为A服务,下面的为B服务。
其中“流量控制”列显示的是对应服务的流量,点击对应服务的流量值,可进行对应A/B服务的流量配置。
|

应用服务
目前服务工作流的应用通常为:对于已创建好的分类模型、回归模型、聚类模型,我们将新的数据输入后,通过模型计算预测出结果。
选择部署服务方式或成功部署服务后,可进行服务的应用。
应用入口:在“服务监控”界面的服务列表中,双击“名称”列中的服务,进入到“服务配置”界面,再单击 服务测试 页签,显示“服务测试”界面:

在“测试数据”文本框中按照示例填写数据,单击 测试 按钮,这些数据进入到当前服务部署的模型中执行后显示测试结果。
对于灰度部署,测试数据将按照流量分配选择A服务、B服务中的一列进行运行,返回最后的测试结果,测试结果即算法选择服务输出的结果。
示例
1、通过数据源或数据预处理定义实验模型,并运行该实验模型。
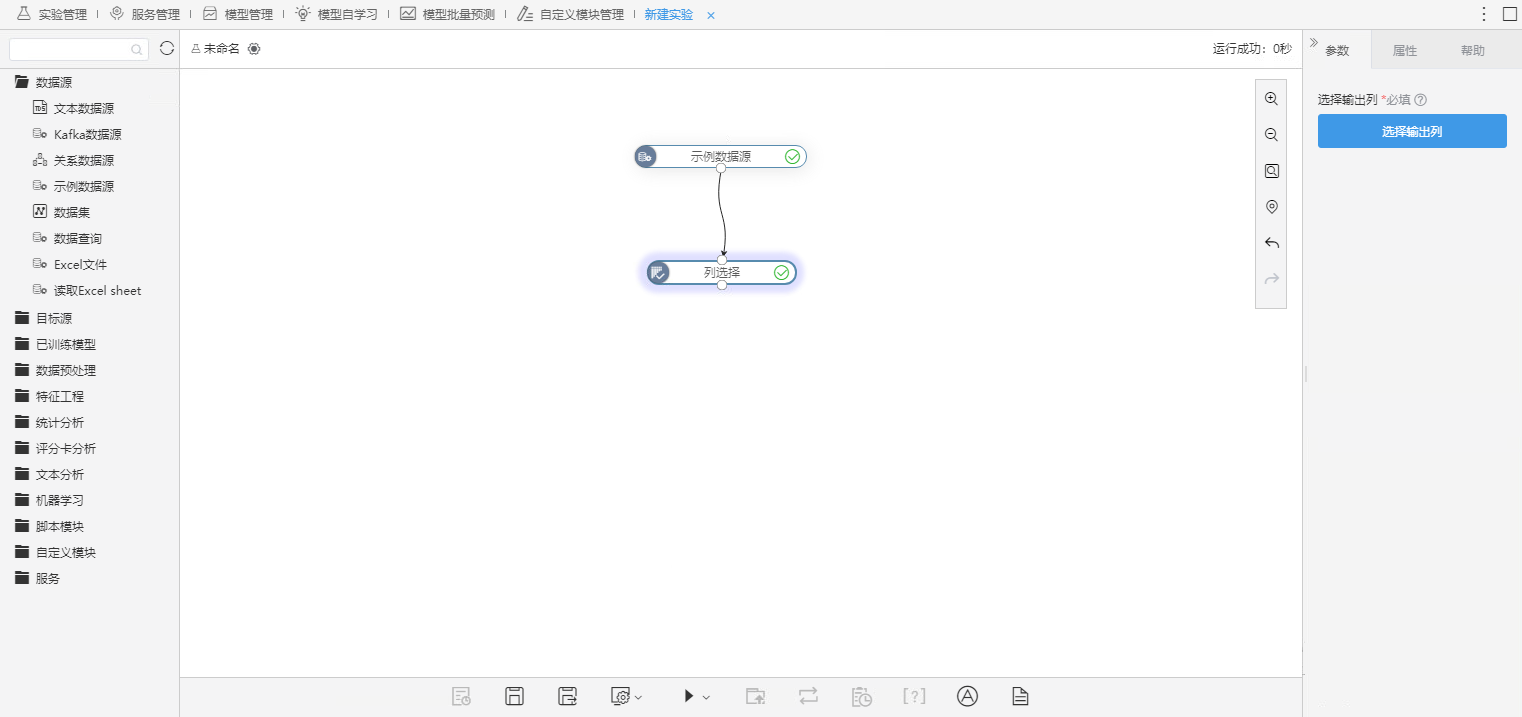
2、拖拽“服务输入”节点到画布,并选择节点,该节点的数据结果是用于服务发布的节点。
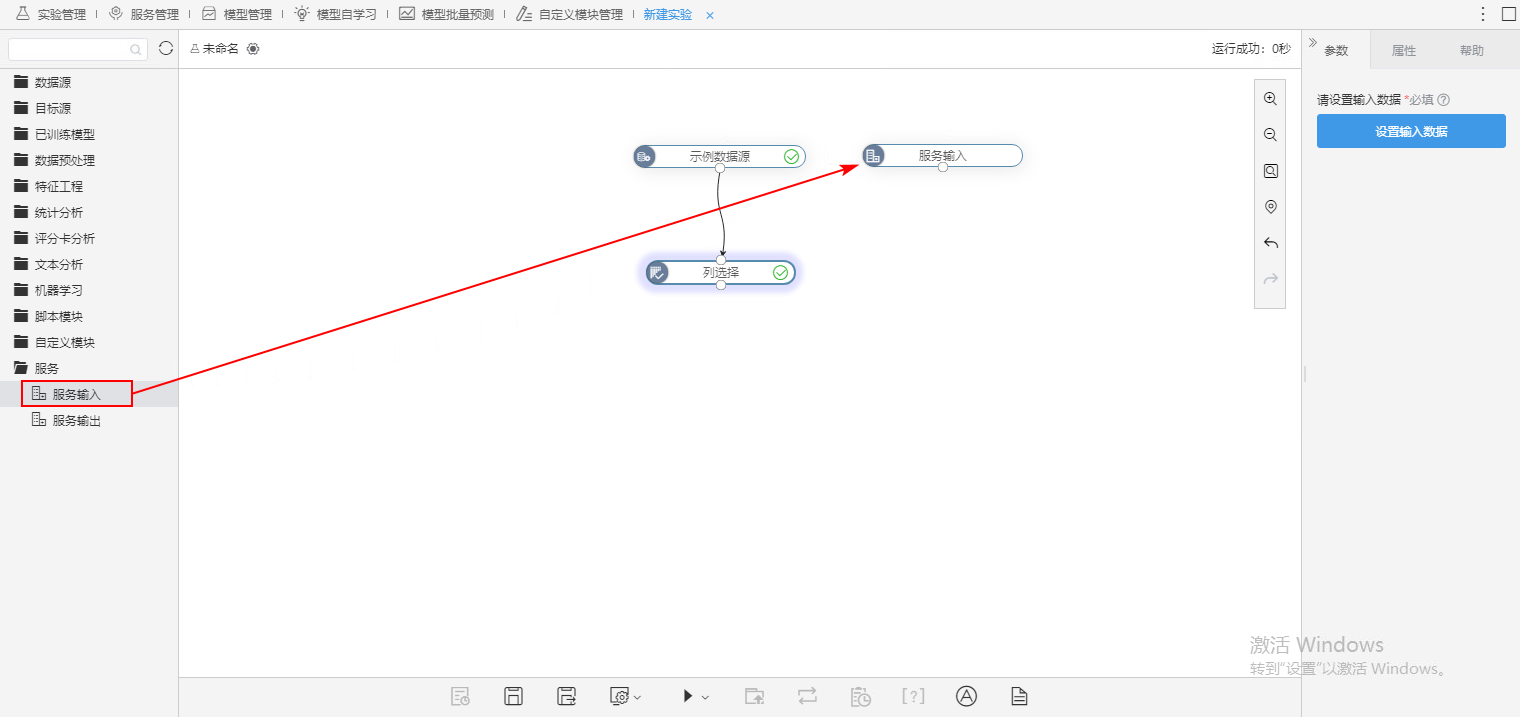
3、将“服务输入”节点在实验模型中替换所选的节点,并将所选节点前的所有节点删除,点击 设置输入数据 按钮。
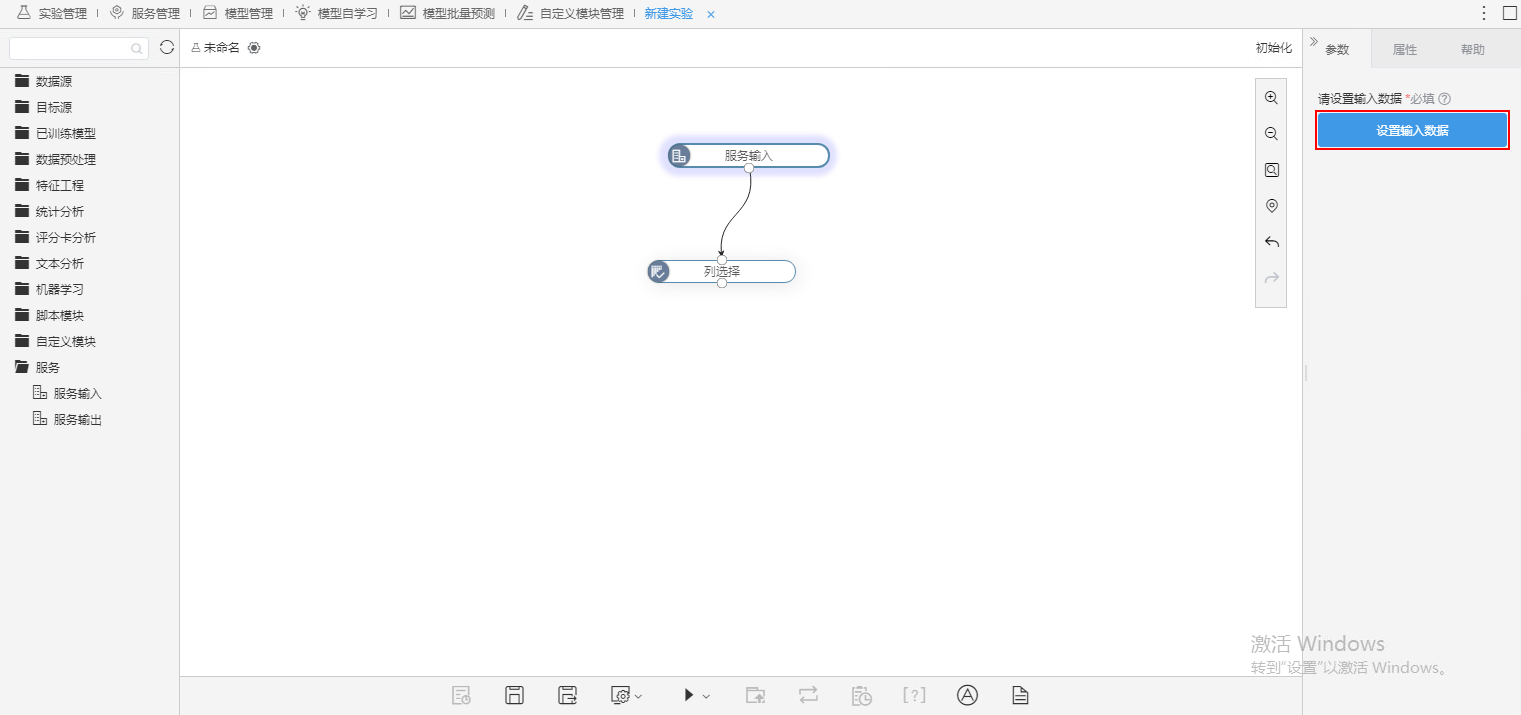
输入数据默认为“选择节点数据”。

4、拖拽“服务输出”节点到流程节点最末,流程执行通过后单击工具栏的 部署服务 按钮。
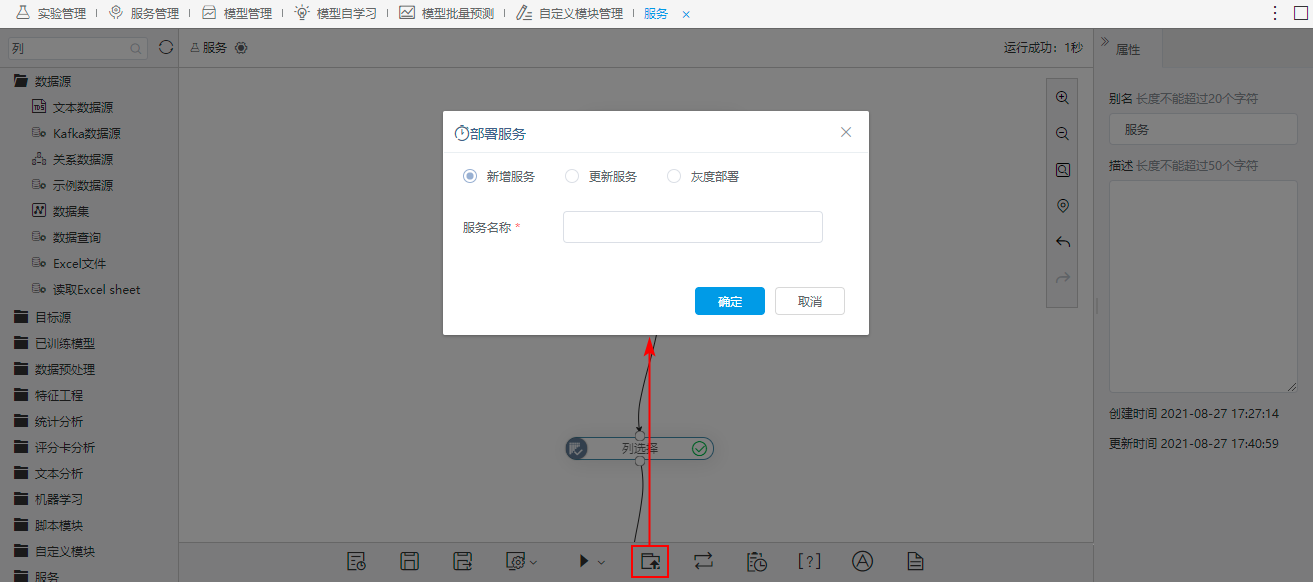
5、选择新增服务并输入服务名称。
 、
、
6、选择“服务测试”页面,点击 测试 按钮对服务进行应用。

7、选择服务管理界面,点击 刷新 按钮,可对新建的服务进行启用、下线、编辑等操作,详情请参考 服务监控 。
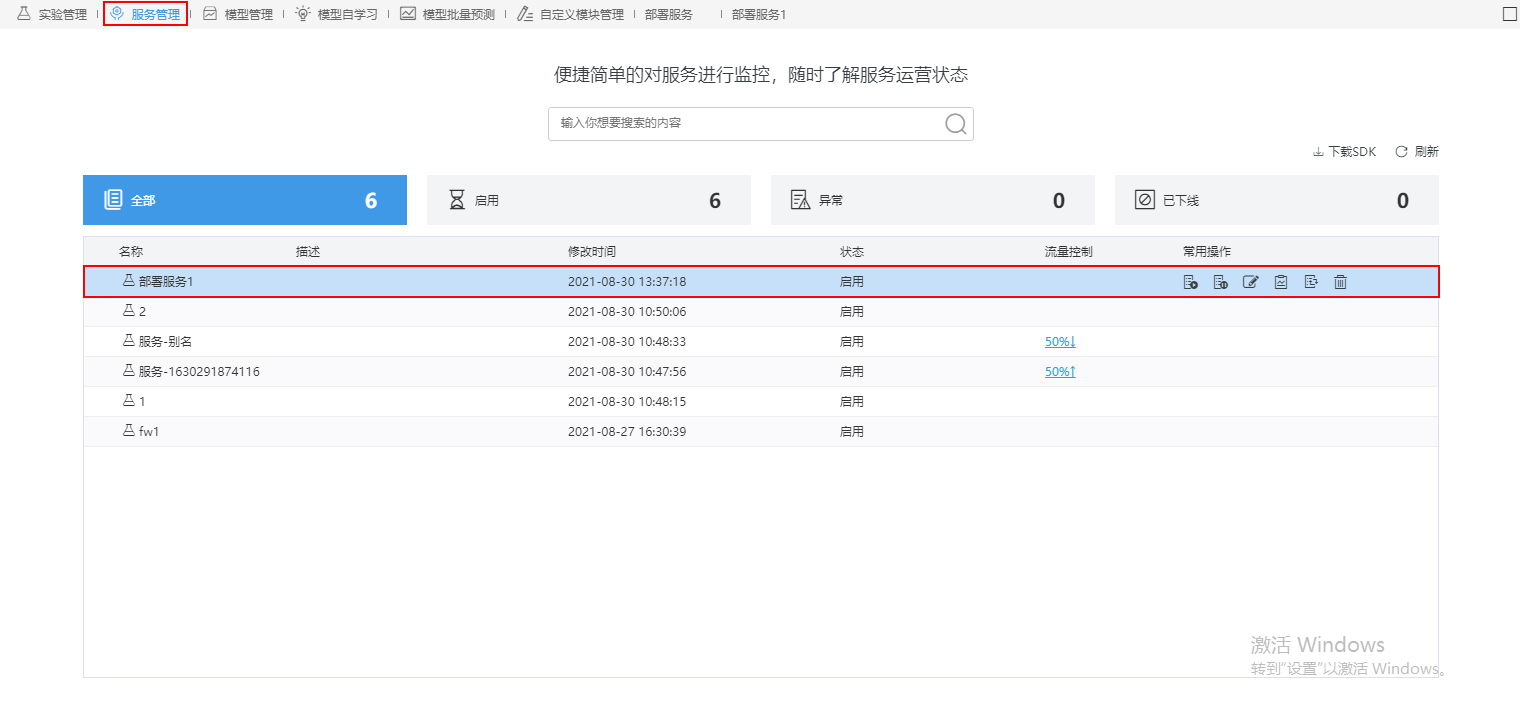
服务监控
服务监控是指对所有已经搭建的服务工作流进行管理。
功能入口:在“数据挖掘”界面中选择 服务管理 页签,显示“服务管理”界面,如下图所示:

该界面分为如下几个区:
- 功能区:用于手动刷新列表和搜索。
操作 | 图标 | 说明 |
|---|---|---|
| 下载SDK |
| 用于将服务提供给其他系统调用。 |
手动刷新 |  | 手动刷新服务列表。 |
搜索服务 |  | 服务流程名称关键字模糊匹配搜索结果。 |
- 状态栏:显示所有服务流程不同状态的统计数据。
- 列表区:显示服务流程列表,支持如下操作:
操作 | 图标 | 说明 |
|---|---|---|
服务启用 |
| 用于启用当前服务流程。 若当前服务呈启用状态,该按钮置灰。 |
服务下线 |
| 用于设置当前服务下线。 若当前服务呈下线状态,该按钮置灰。 |
编辑 |
| 用于编辑当前服务,进入“服务配置”界面(如下图所示),支持修改服务的别名和描述。
|
| 服务调用统计 |
| 用于对某个时间段服务调用执行记录进行统计。
|
| 服务调用记录 |
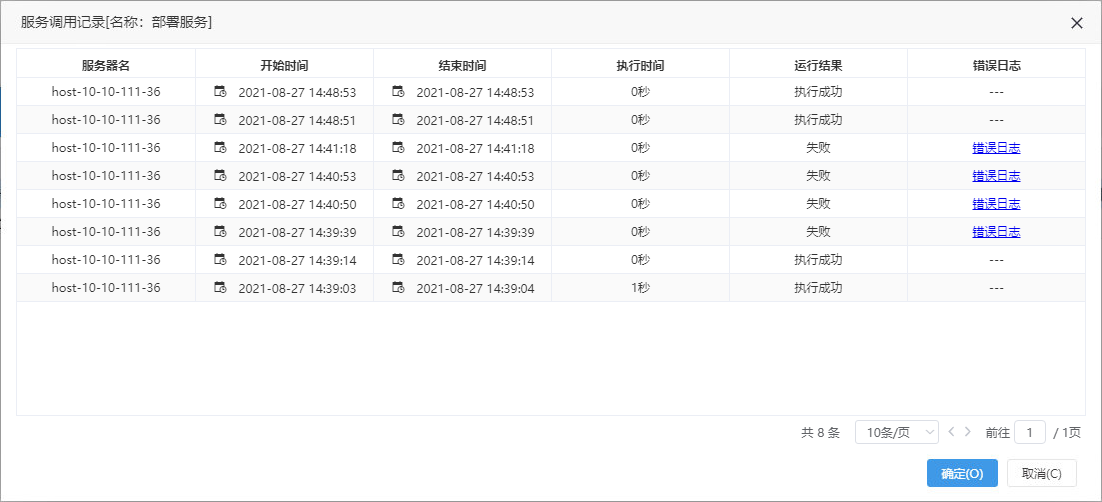
| 记录了服务调用的服务器名、开始时间、结束时间、执行时间、运行结果、错误日志等信息。可用于监控模型的运行时长、稳定性等。
错误日志:在资源有限的情况下,用于排查某个模型服务卡死。只有执行失败的服务记录才会有错误日志,点击错误日志即可下载日志到本地查看。 |
删除 |
| 用于删除当前服务流程。 |


服务监控只能使用ClickHouse高速缓存库,如果更改了错误的高速缓存库,需要重启服务引擎后才能使用。
服务调用示例
调用流程说明:
1. 示例附件(ServiceInvokeDemo.zip)解压后,得到Demo目录结构如下:

2. 各目录说明
1) doc——文档目录,demo说明文档在该目录下。
2) example——服务示例目录,自带一个可运行的服务Dag示例,可以在平台中进行流程导入,并部署成服务。
3) java——java语言编写的demo工程,该项目为maven工程,可以使用开发工具以maven项目的形式进行导入,maven环境自行安装。
4) python——python语言编写的demo工程,开发工具以python项目的形式进行导入,python环境自行安装(推荐使用anaconda3和python3.6及其以上版本)。
3. 调用执行
1) java语言,成功导入工程后,在ServiceInvokeDemo.java文件中根据实际调用的服务环境,修改对应的ip、端口、服务ID和输入数据,然后运行。运行成功返回如图所示:

备注:该图片返回数据是自带服务Dag示例的返回数据。如果不是使用该服务示例,可能返回数据有一定差异。
2) python语言,成功导入工程后,在ServiceInvokeDemo.py文件中根据实际调用的服务环境,修改对应的ip、端口、服务ID和输入数据,然后运行。运行成功返回如图所示:

备注:该图片返回数据是自带服务Dag示例的返回数据。如果不是使用该服务示例,可能返回数据有一定差异。


